Some of the instances are equipped with the new AMD EPYC Rome CPUS.
In the case of Google’s n2d-highcpu-224 it comes with 224 Virtual CPUs (Cores).
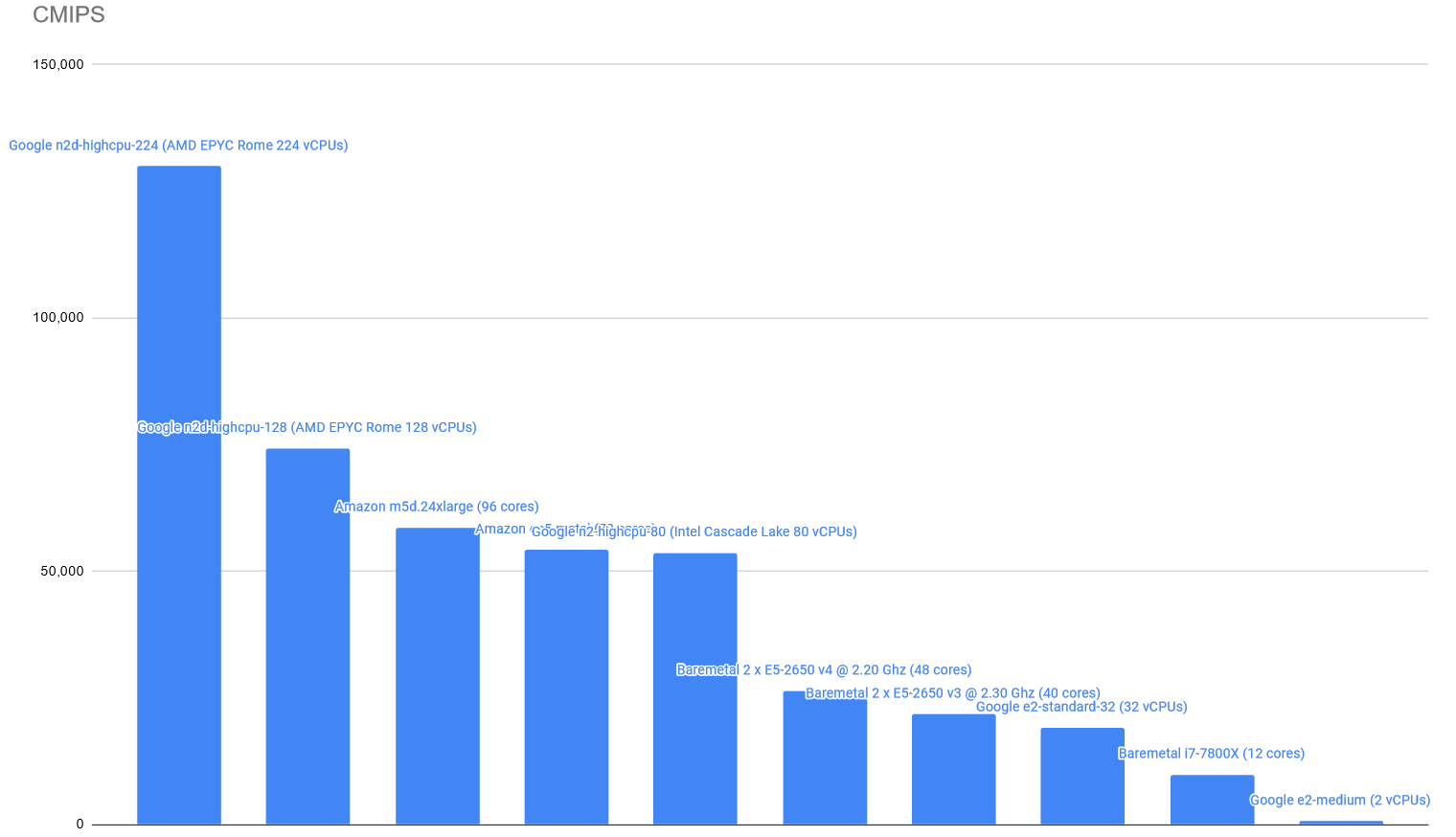
The CMIPS score is:
Some of the instances are equipped with the new AMD EPYC Rome CPUS.
In the case of Google’s n2d-highcpu-224 it comes with 224 Virtual CPUs (Cores).
The CMIPS score is:
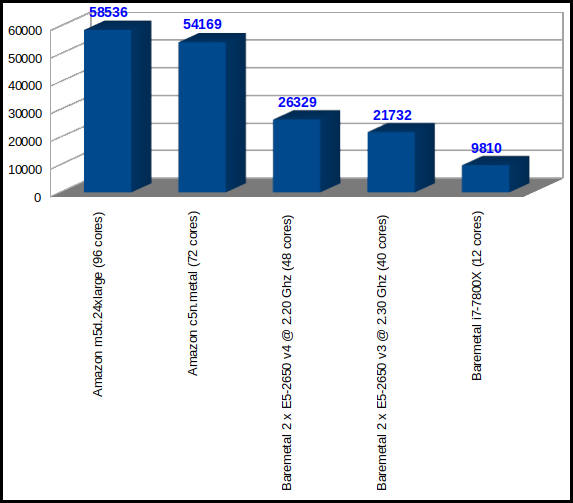
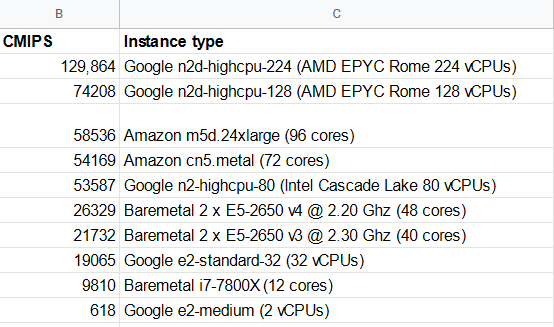
The latest instances from Amazon AWS Compute optimized compared versus two baremetals with 2 processors each, and one single Desktop Intel i7-7800X processor.
| CMIPS Score | Execution time (seconds) | Type of instance | Total cores | CPU model |
| 58536 | 34.16 | Amazon AWS m5d.24xlarge | 96 | Intel(R) Xeon(R) Platinum 8175M CPU @ 2.50GHz |
| 54169 | 36.92 | Amazon AWS c5n.metal | 72 | Intel(R) Xeon(R) Platinum 8124M CPU @ 3.00GHz |
| 26329 | 75.96 | Baremetal | 48 | Intel(R) Xeon(R) CPU E5-2650 v4 @ 2.20GHz |
| 21732 | 92.02 | Baremetal | 40 | Intel(R) Xeon(R) CPU E5-2650 v3 @ 2.30GHz |
| 9810 | 203.87 | Desktop computer | 12 | Intel(R) Core(TM) i7-7800X CPU @ 3.50 GHz |
I was anticipating the migration of one of the projects I work for as CTO, from Microsoft Azure, cause #AzureDown issue, and I published a tweet about it.
One Google guy invited me to check Google Cloud and I asked for a voucher to test the newly added features of the platform and publishing the results at cmips.
I tested Google when I was in charge of Easy Cloud Managed project, but at that time Google had the App Engine, but not the Compute Engine.
He put me in contact with three wonderful Engineers that talked to me about some de facto standard software for performance benchmarking, and shown me some statistics from other projects. I explained that I wanted to test the real use that applications like Apache or Mysql do, and that I want to detect Clouds that outsell their memory (like 10% or more in excess) and so for real the host swaps and the guest instances are slow, I explained how I test, the most real for the Start ups needs, and why I wrote cmips (source code) from the scratch, with multi thread and only CPU + RAM speed computation operations, and no system calls that could distort the results (hypervisors do many tricks to improve performance).
Like Amazon, Google offers a lot of tools and services. I like specially the possibility to have your code and Google scaling to the number of Servers you need, transparently, in the same architecture they use with Google App. But because good Engineers are Software Artisans, that require full control and using very custom solutions for the requirements of the Start ups, I will focus on Google Compute Engine, that is the equivalent to Virtual Machines/Instances, that is what we evaluate at cmips.
The first I notice is that there is a Free Voucher for trialling, of 300 $USD or 2 months. I notice also that Google Compute Engine charges per 10 minute intervals.
2016-06-30 Correction: Paul Nash from google was so kind to point me that I had an error in my understanding of the price politic. As he said “[…]we charge per minute, but there is a 10 minute initial minimum when the VM starts. After that it is per minute[…]”. Thanks for the clarification
Some providers charge by the hour, few -like Microsoft Azure- by the minute. Few charge by the day.
Like in the case of Amazon the Free Voucher is very limited. You can only launch smaller models. From f1-micro (1 core in Shared CPU) to n1-standard-2 (2 vCPU and 7.5 GB RAM).
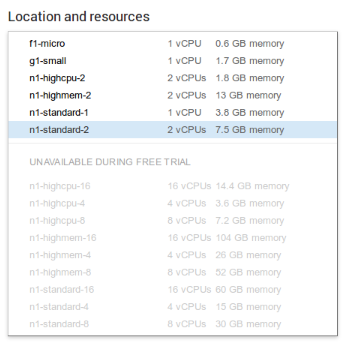 As you can see the list is not sorted by power, but by name (so n1-highcpu-16 comes before n1-highcpu-4 because 1, from 16, goes before 4).
As you can see the list is not sorted by power, but by name (so n1-highcpu-16 comes before n1-highcpu-4 because 1, from 16, goes before 4).
Like in the case of Amazon the models are pre-set: x vCPU, y GB RAM, etc… Only CloudSigma (that has its own hypervisor), LunaCloud (with less powerful servers) and few more allow you freely to customize the balance on the amounts of computing power and ram and so not paying for what you don’t need.
All the instances are 64 bit, Intel based. The only one we have found to have additional support for Sun (Oracle) Solaris SPARC is CloudSigma.
When I registered all the process came in Spanish. I’ve my google account in Catalan, but as it is not available automatically it showed everything. I would have preferred to browse all the process in English instead but there was no way to change the language for the registration process. That’s why some screen captures are in Spanish, until I was registered, and so able to switch to English.
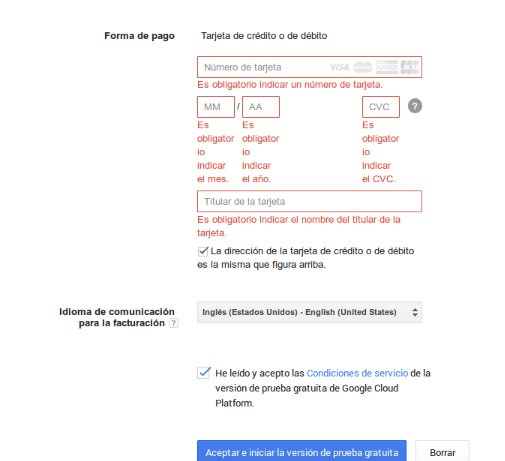
Like in many providers, Visa card is required, although it is no charged. I guess that’s a measure for validation like Amazon does.
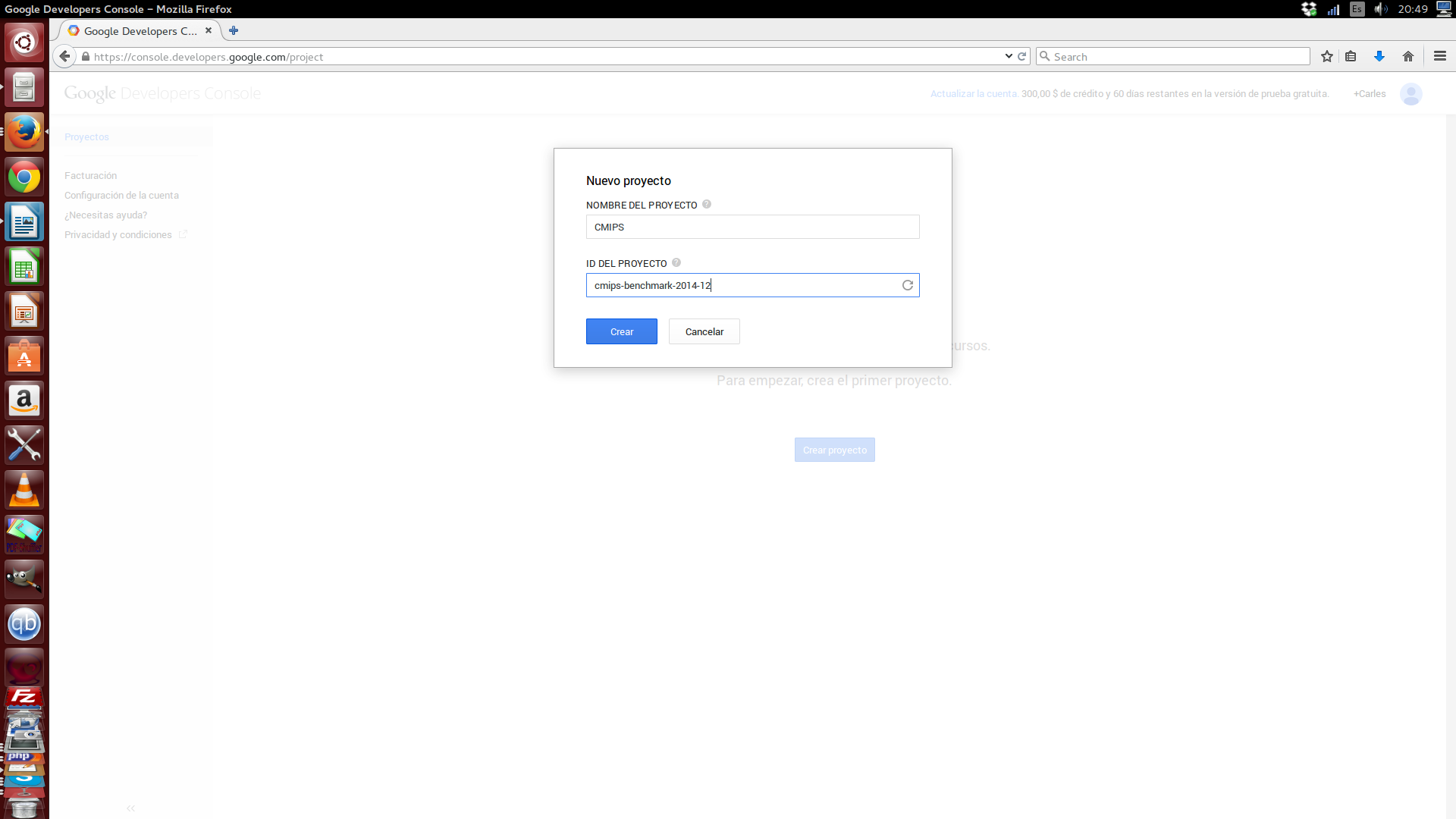
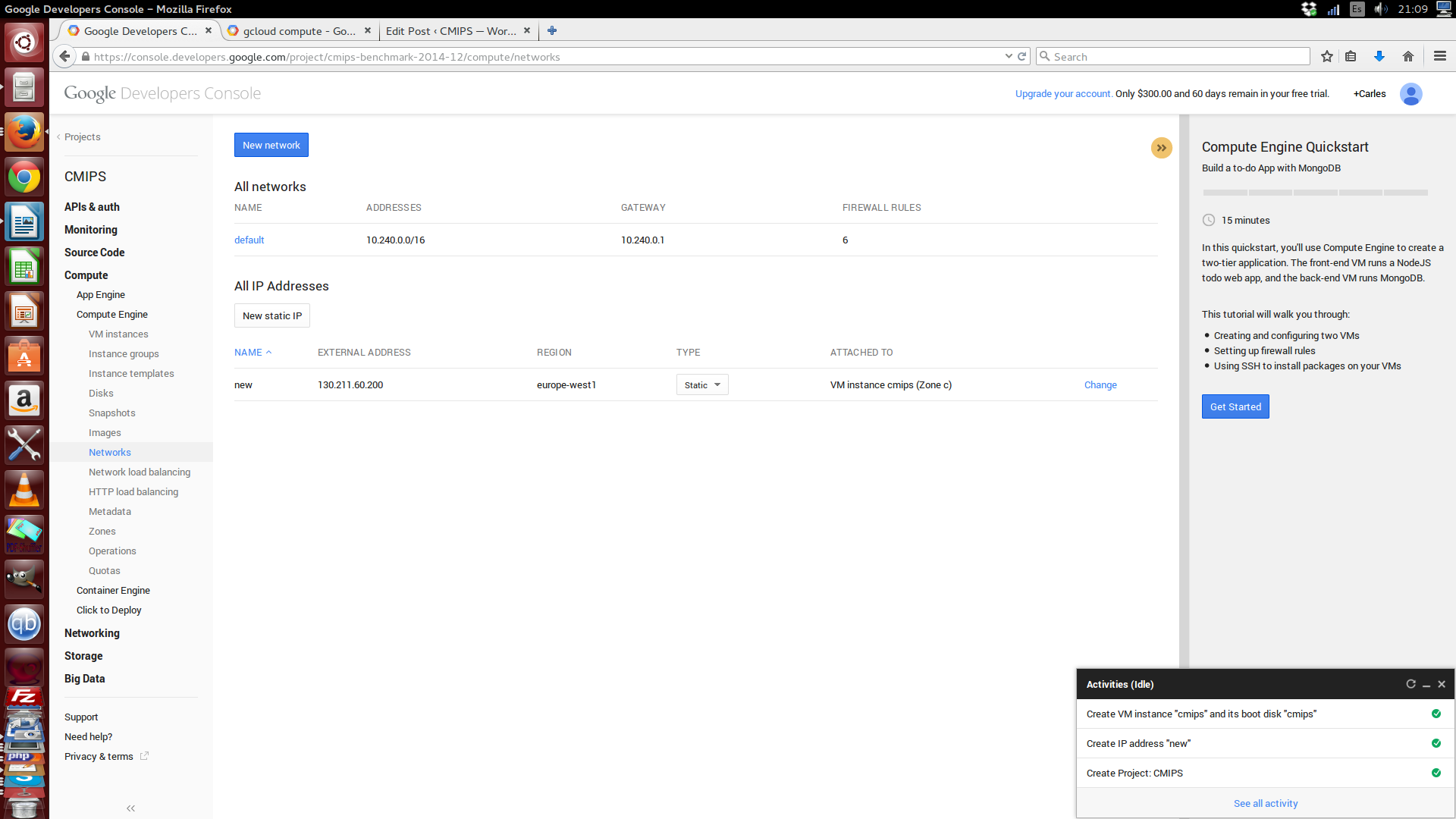
 Once you have registered, to start, you must create a Project.
Once you have registered, to start, you must create a Project.
The interface clearly remembers me a mix between first versions of Amazon AWS and Microsoft Azure.
With the status widget down, it comes a very useful option, that is the ability to retry an operation that failed.
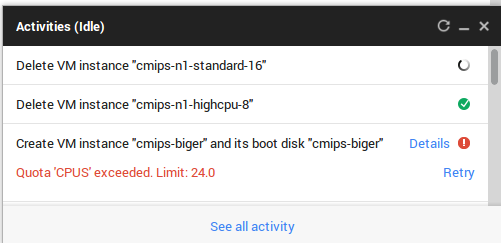
An interesting option for developers is that from the very first moment they have a wizard step by step to learn how to create an application with several servers and a MongoDb database.
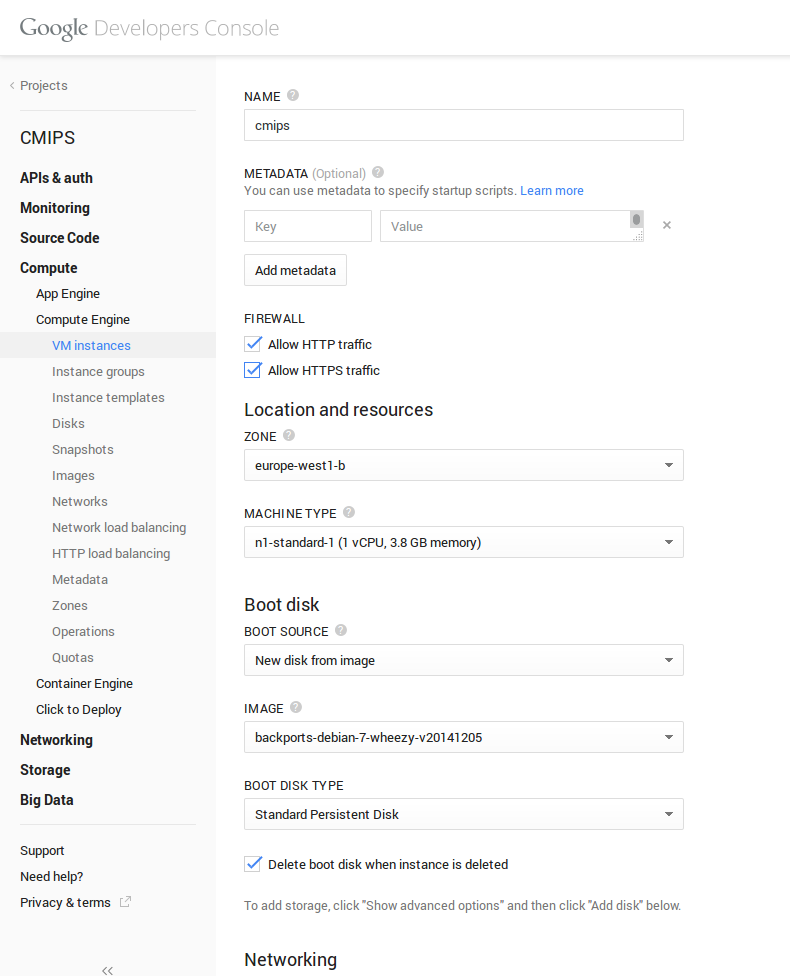
When launching an instance it is a very good point that they allow metadata (like cloudinit), in order to launch your scripts when the machine is created. That’s a good point.
It is powerful as concept but has a lot to improve, as it is really user unfriendly (take a look at ECManaged, or not so cool but Ok RightScale, or Amazon User Data to see why).
The easy of use, and a reasonable common sense for the easy to use of the advanced features like cloud-init/user data/metadata, portability and re-usability, is the missing point of most of the Cloud providers. Most developers have no clue on systems, base64, etc… so Cloud Systems have to make things easier and specially auto-scaling and error-proof. This is one of the points I insisted to Amazon when I was in their offices in Dublin.
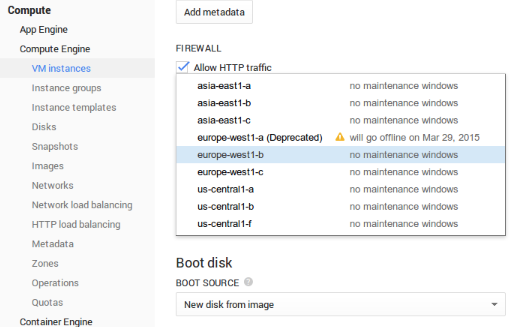
 It is cool that in the zone selection drop-down, it is indicated the future maintenance windows. It’s always cool to know that there will be a maintenance if you plan to release something.
It is cool that in the zone selection drop-down, it is indicated the future maintenance windows. It’s always cool to know that there will be a maintenance if you plan to release something.
The base images are the most popular and updated very often. Date of the last creation of the images is provided clearly.
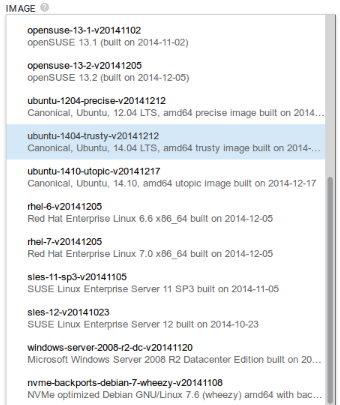
So when I installed my Ubuntu 14.10 Server images, and I did apt-get upgrade there was nothing to upgrade. Everything was up to date. The Ubuntu base image was created on 2014-12-17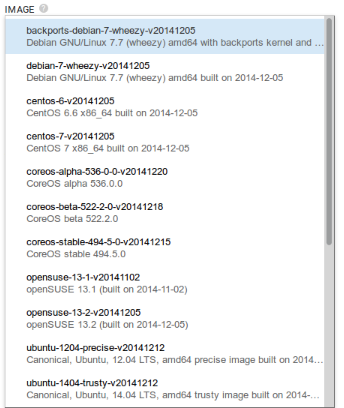
The user interface is a bit Spartan. It looks to me like developers that first created the REST API, created a user friendly interface quickly just to sell the service, but in it’s nature is a REST/gcloud command line tool application. (Yes, they have a set of command-line tools, like Amazon has)
I say that because I was able to trick a bit the validations of the interface and despite spaces not being accepted, they “eat” them all if I put the spaces at the beginning, like ” Test”.
Also ” Eat this——————–” is accepted.
The spaces at the beginning are trimmed later, but I think a good user interface should take care of aspects like this. Tricky spaces at the end doesn’t raise an error.
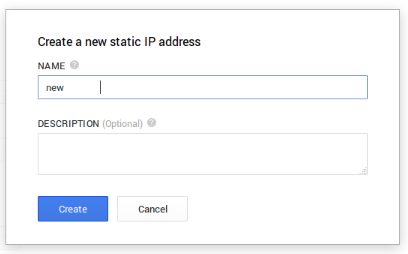
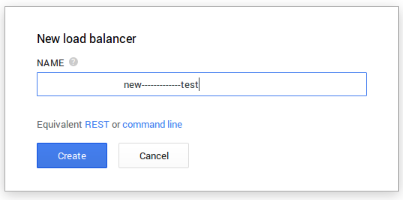
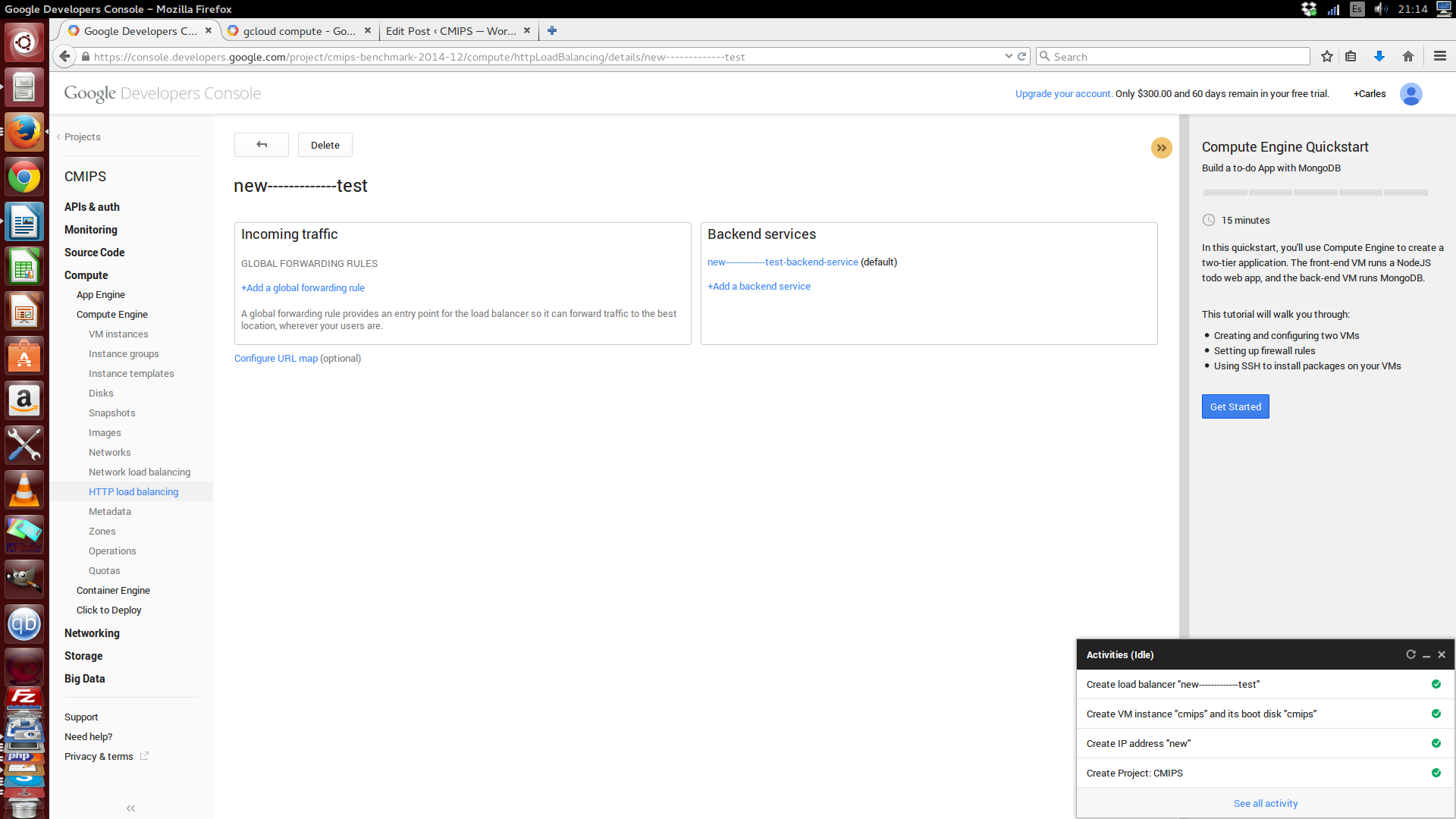
It is annoying that at the beginning you don’t know that you can’t use spaces for the name of different object, and is a bit confusing that the name is used as the ID.
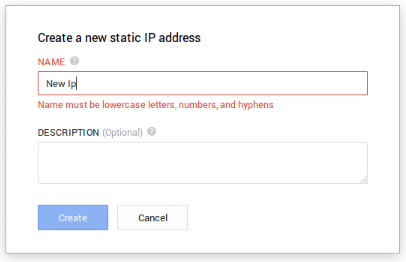
So if I send request via the RESTFul API, and I don’t know that an object with that name/id exists, the operation will fail. Amazon uses names as something nice for the user, but internally always works with ids (based on UUID).
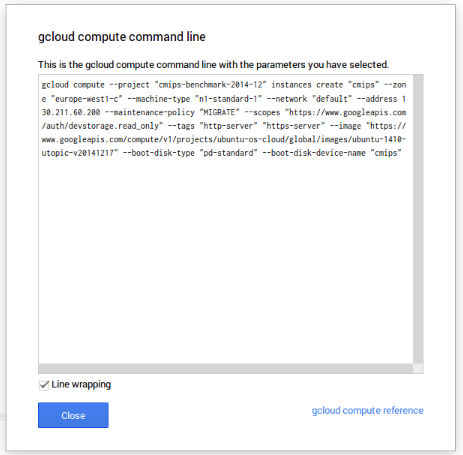
A very good point is that all the pages of the console, have the Equivalent REST command.
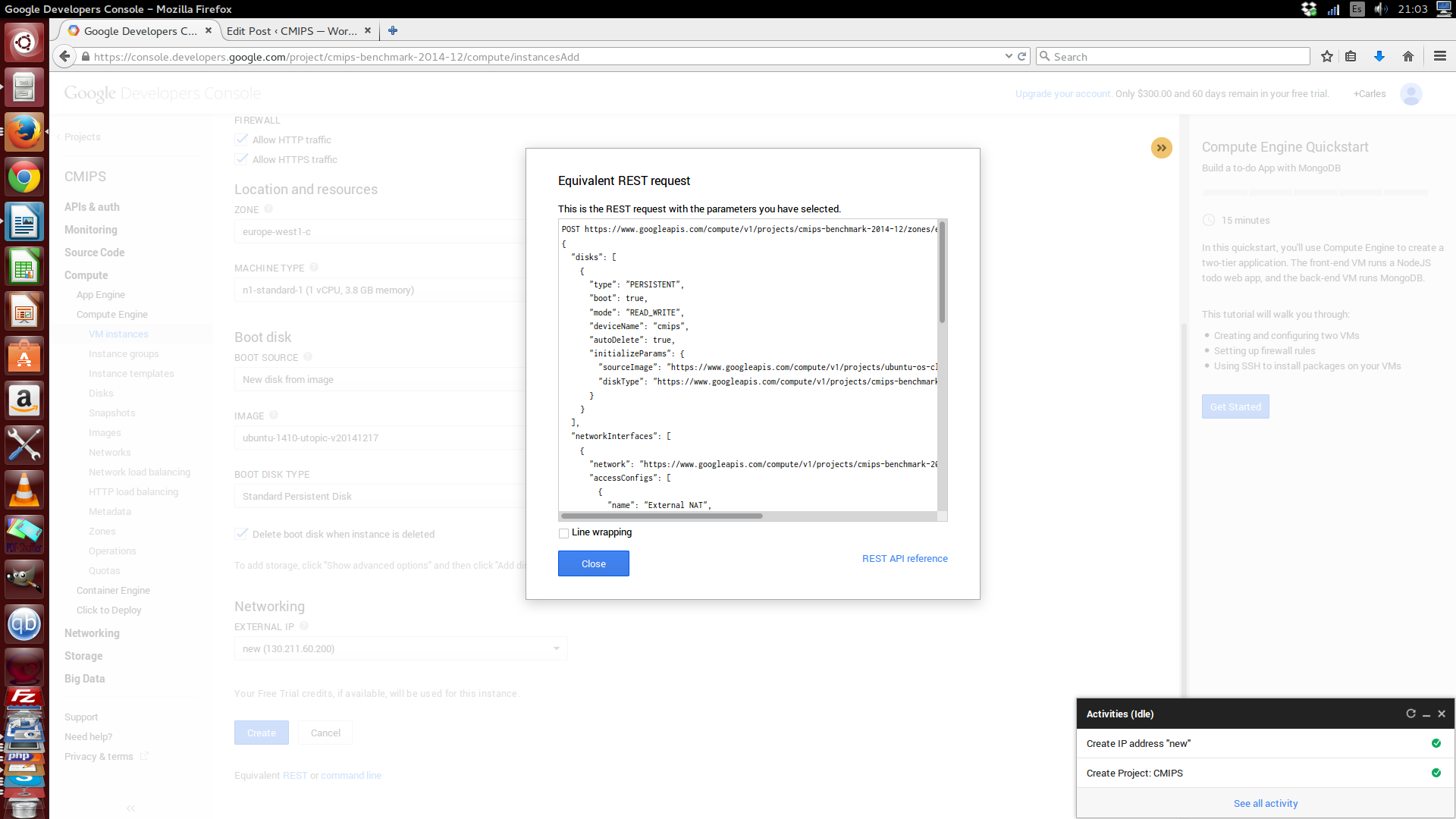 An improvement would be to be able to copy the REST message formatted, as it is copied without spaces (just for improved reading).
An improvement would be to be able to copy the REST message formatted, as it is copied without spaces (just for improved reading).
So you can easily adapt for your automatic processes.
POST https://www.googleapis.com/compute/v1/projects/cmips-benchmark-2014-12/zones/europe-west1-c/instances { "disks": [ { "type": "PERSISTENT", "boot": true, "mode": "READ_WRITE", "deviceName": "cmips", "autoDelete": true, "initializeParams": { "sourceImage": "https://www.googleapis.com/compute/v1/projects/ubuntu-os-cloud/global/images/ubuntu-1410-utopic-v20141217", "diskType": "https://www.googleapis.com/compute/v1/projects/cmips-benchmark-2014-12/zones/europe-west1-c/diskTypes/pd-standard" } } ], "networkInterfaces": [ { "network": "https://www.googleapis.com/compute/v1/projects/cmips-benchmark-2014-12/global/networks/default", "accessConfigs": [ { "name": "External NAT", "type": "ONE_TO_ONE_NAT", "natIP": "130.211.60.200" } ] } ], "metadata": { "items": [] }, "tags": { "items": [ "http-server", "https-server" ] }, "zone": "https://www.googleapis.com/compute/v1/projects/cmips-benchmark-2014-12/zones/europe-west1-c", "canIpForward": false, "scheduling": { "automaticRestart": true, "onHostMaintenance": "MIGRATE" }, "name": "cmips", "machineType": "https://www.googleapis.com/compute/v1/projects/cmips-benchmark-2014-12/zones/europe-west1-c/machineTypes/n1-standard-1", "serviceAccounts": [ { "email": "default", "scopes": [ "https://www.googleapis.com/auth/devstorage.read_only" ] } ] }
gcloud compute --project "cmips-benchmark-2014-12" instances create "cmips" --zone "europe-west1-c" --machine-type "n1-standard-1" --network "default" --address 130.211.60.200 --maintenance-policy "MIGRATE" --scopes "https://www.googleapis.com/auth/devstorage.read_only" --tags "http-server" "https-server" --image "https://www.googleapis.com/compute/v1/projects/ubuntu-os-cloud/global/images/ubuntu-1410-utopic-v20141217" --boot-disk-type "pd-standard" --boot-disk-device-name "cmips"
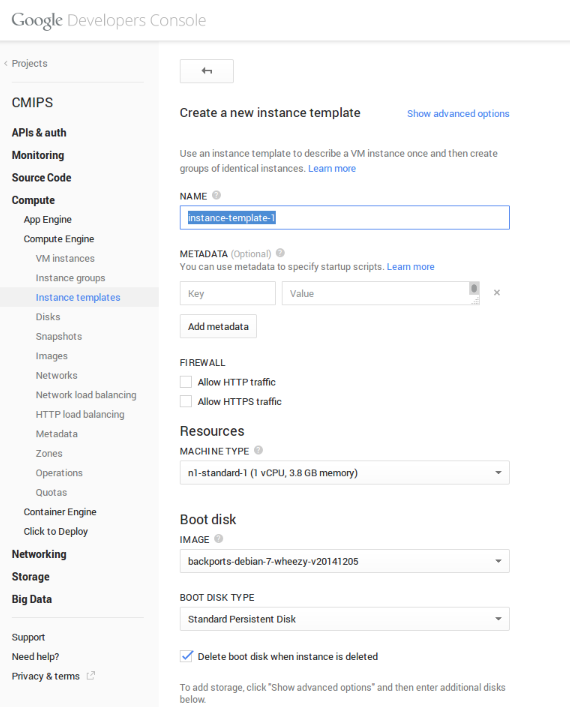
Instance templates are a bit like what I created for ECManaged, but google’s much much much less powerful. It allows to create a template for the most common aspects, like the base image, etc… but nothing to be with more portable, advanced and powerful solutions supporting deploying Base Software from puppet, chef, code from git/svn, running multiple scripts in order with error control and decision case…
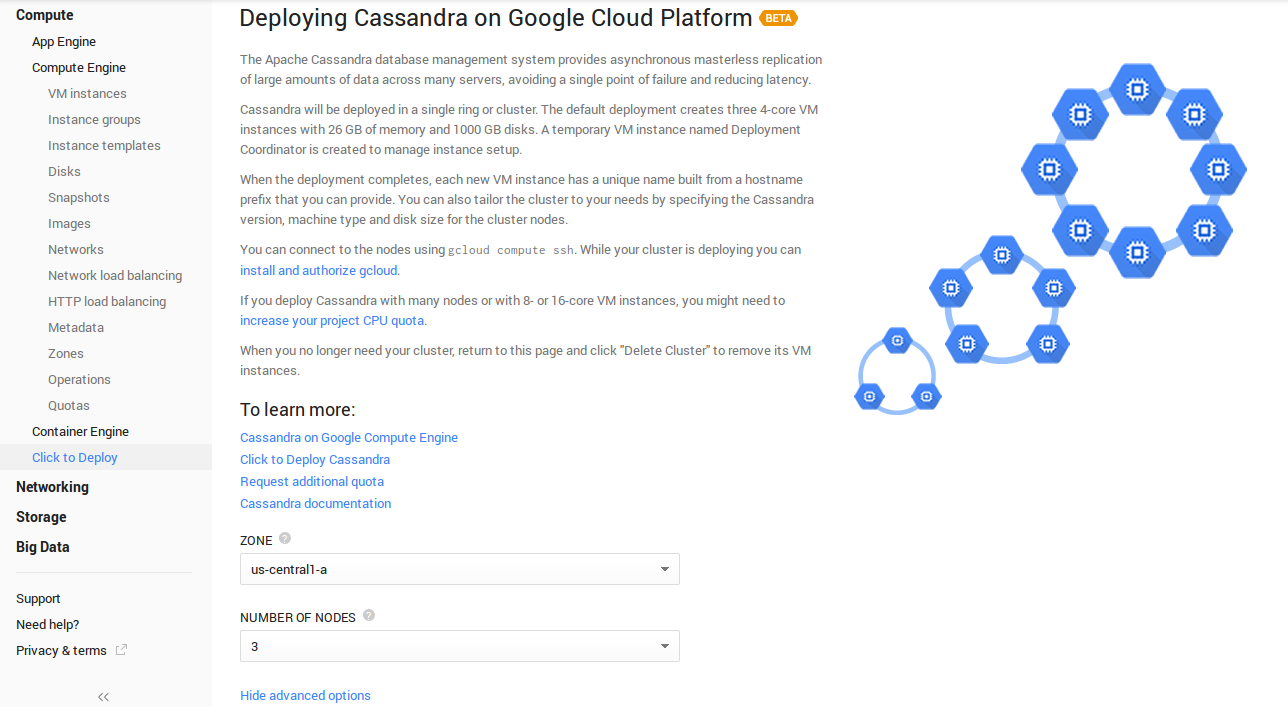
The Apps, a bit more customizable way to launch projects composed by several servers, where you can choose the number of nodes, version of Software, etc… are a fraction of the advanced functionalities I’m explaining about templating, but are in the good direction.
A Health check is incorporated, able to check http/https, and that’s always nice. I use several external professional services for that, and it’s cool to know that Google includes this for free.
Network options are cool, but complicated for newbies, allowing you to create private networks. In fact the instances have a private address that is mapped (NAT) to the public Ip. This is very important to know as some programs may require special configurations.
 One thing that I think is an epic win about using google cloud is that your web will be in the same infrastructure as google, I mean that the times, the latency of the Tcp/Ip packets, between google and your instance are incredibly low. As you may know one of the things that is very important for SEO is the response time. With a super-low latency your website will always have faster response times to google. I was sondering so if this translates in that instances in google cloud would probably have a better Page Rank.
One thing that I think is an epic win about using google cloud is that your web will be in the same infrastructure as google, I mean that the times, the latency of the Tcp/Ip packets, between google and your instance are incredibly low. As you may know one of the things that is very important for SEO is the response time. With a super-low latency your website will always have faster response times to google. I was sondering so if this translates in that instances in google cloud would probably have a better Page Rank.
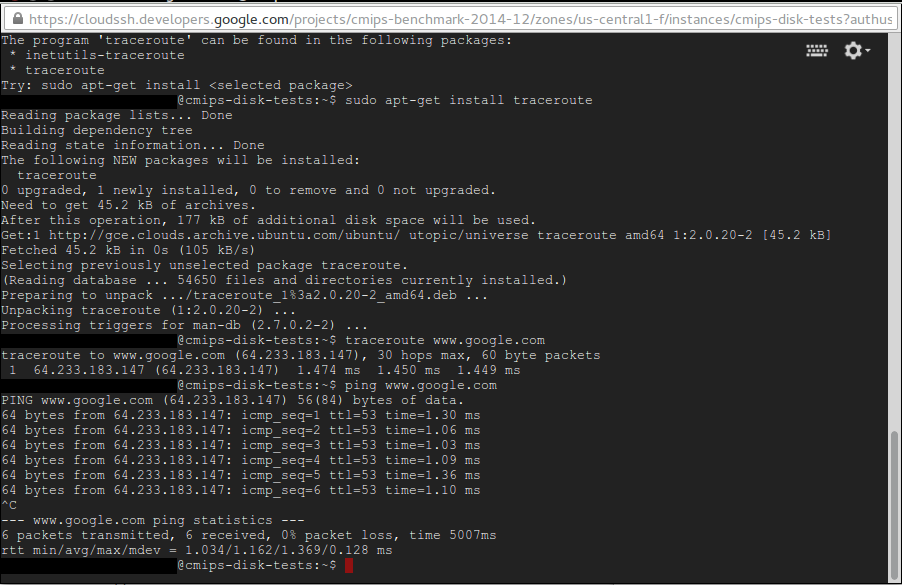
Doing traceroute brings you direct to google, doing ping returns 1 ms. This is really good for SEO.
 I asked about this to the Team at google and they told me that:
I asked about this to the Team at google and they told me that:
“I asked a number groups about this one. The general consensus is we do nothing to favor sites hosted on GCP and any latency benefit if one existed will be negligible in terms of SEO.
I has not tested Google Cloud Storage but looks like an interesting option.
I did not found were to download the ssh key (cert) they have created by default or ability to create one on Google for the servers directly. Fortunately there is a Web SSH Client and the console sends the keys to Web SSH Client, so you can access the Server and add whatever you need. SSH port is open to worldwide by default. (And I can assure there are robots trying to access your Server from the very first moment)
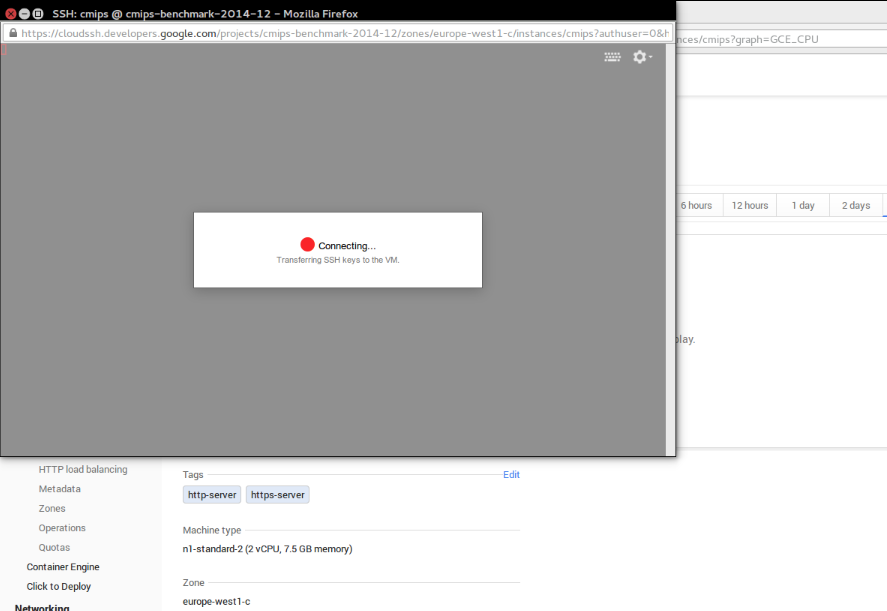 The user for the connection is your email, so I’ve deleted that part from the image:
The user for the connection is your email, so I’ve deleted that part from the image:
That’s a bit disturbing when you notice, and will force developers taking screenshots to publish on the web to hide sections of the image like I did.
Must say the Web SSH client is one of the bests I’ve tested, supporting copy and paste (CTRL C, CTRL V), offering colors, etc…
I miss the right click, that I can use with the Amazon interface, that is not possible in google cloud web.
There is no STOP. Only Reboot and DELETE. You cannot stop an instance, and if you shutdown the server from command line the machine stops and you’re not able to restart it. Fortunately the disk is not deleted by manually shutdowning and you can generate a snapshot and launch a new instance using this snapshot.
Google just contacted me to tell me that the STOP button just got implemented. However documentation tells that:
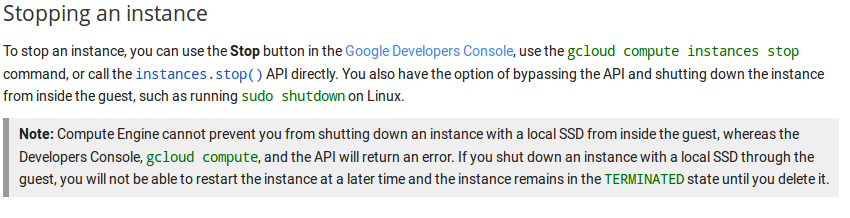 So on SSD perhaps is not the best option.
So on SSD perhaps is not the best option.
Having no STOP is annoying. Many use snapshots for doing backups, but generating an snapshot of a live system, not stopped, could end in a corrupted mysql database in the snapshot. Really not appealing.
The Clone button is really confusing, as for real it does launching a new instance. One may except from this to have a snapshot and launch of new instance, but only clones the properties, like the base image used.
Price and remaining free account time, shown at the top, is not updated in real time.
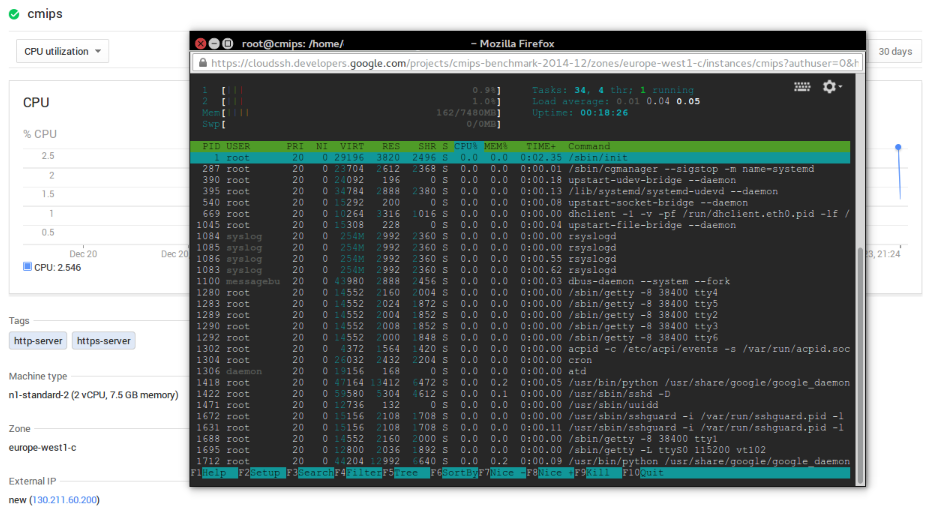
Graphical stats of CPU use are not accurate, as they are aggregated at Project Level, what is a mess if you deal with few VM’s instead of autoscaling apps, like in the case of Windows Azure. It works better that Azure but don’t trust it at all. It approximates and aggregates. One ends looking for one single server, and in the past hour.
In this sample, when we benchmark the CPU is at 100%, all of them, see how confusing it is presented:
Resizing the instance -like you can do in Amazon- is not possible. You must create a snapshot and then launch a new instance from this.
sshguard is installed, blocking tries to hack. And they try from the very first moment.
Dec 24 19:41:25 cmips-1 sshguard[1590]: Blocking 211.129.208.67:4 for >630secs: 40 danger in 4 attacks over 6 seconds (all: 40d in 1 abuses over 6s).
Dec 25 01:12:25 cmips-1 sshd[14646]: reverse mapping checking getaddrinfo for huzhou.ctc.mx.fund123.cn [122.225.97.87] failed - POSSIBLE BREAK-IN ATTEMPT
The instances have swap disabled by default. I’m seeing this in several providers lastly, like Azure. I guess they do for performance, (to avoid having swap -that goes over the network- overloading the host and network) but it’s annoying to have to setup the swap for every instance. (having no swap is bad many times, as if it exceeds the threshold of available memory applications crash or are killed, swap is recommended in many cases)
I tried what happens if I pm-suspend the instance, nothing happens.
The web doesn’t refresh after certain operations like delete the instance.
I upgraded to the paid account, but in Europe I was not able to launch instances of more than 2 vCPU. There was no capacity it said. I had to test in US zones.
I had a similar issue recently within Amazon Cloud, in the new Datacenter Frankfurt, Germany, but with a much more powerful server, the c3.8xlarge. Is a good machine, but I was only able to launch up to c3.4xlarge due to not more capacity in Frankfurt it said, so I moved the project to Ireland where I had access to full horsepower.
They have a pricing calculator:
https://cloud.google.com/pricing/?hl=en_US
The price policy is really interesting:
Once you use an instance for over 25% of a billing cycle, your price starts dropping. This discount is applied automatically, with no sign-up or up-front commitment required. If you use an instance for 100% of the billing cycle, you get a 30% net discount over our already low prices.
https://cloud.google.com/compute/pricing#sustained_use
CPU reports to be a Intel Xeon at 2.50 Ghz, but this is intercepted by the hypervisor software. I can’t say certainly what CPU model they are using.
With the superior model n2-highcpu-16 the CPU is reported to be a Intel Xeon at 2.60 Ghz:
grep -i --color "model name" /proc/cpuinfo
The detailed report (of one core):
processor : 15 vendor_id : GenuineIntel cpu family : 6 model : 45 model name : Intel(R) Xeon(R) CPU @ 2.60GHz stepping : 7 microcode : 0x1 cpu MHz : 2599.998 cache size : 20480 KB physical id : 0 siblings : 16 core id : 7 cpu cores : 8 apicid : 15 initial apicid : 15 fpu : yes fpu_exception : yes cpuid level : 13 wp : yes flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ss ht syscall nx pdpe1gb rdtscp lm constant_tsc nopl xtopology eagerfpu pni pclmulqdq ssse3 cx16 sse4_1 sse4_2 x2apic popcnt aes xsave avx hypervisor lahf_lm xsaveopt bogomips : 5199.99 clflush size : 64 cache_alignment : 64 address sizes : 46 bits physical, 48 bits virtual power management:
The solution is very complete, having incorporated the ability to create Network Load Balancers and HTTP Load Balancers for easily scaling.
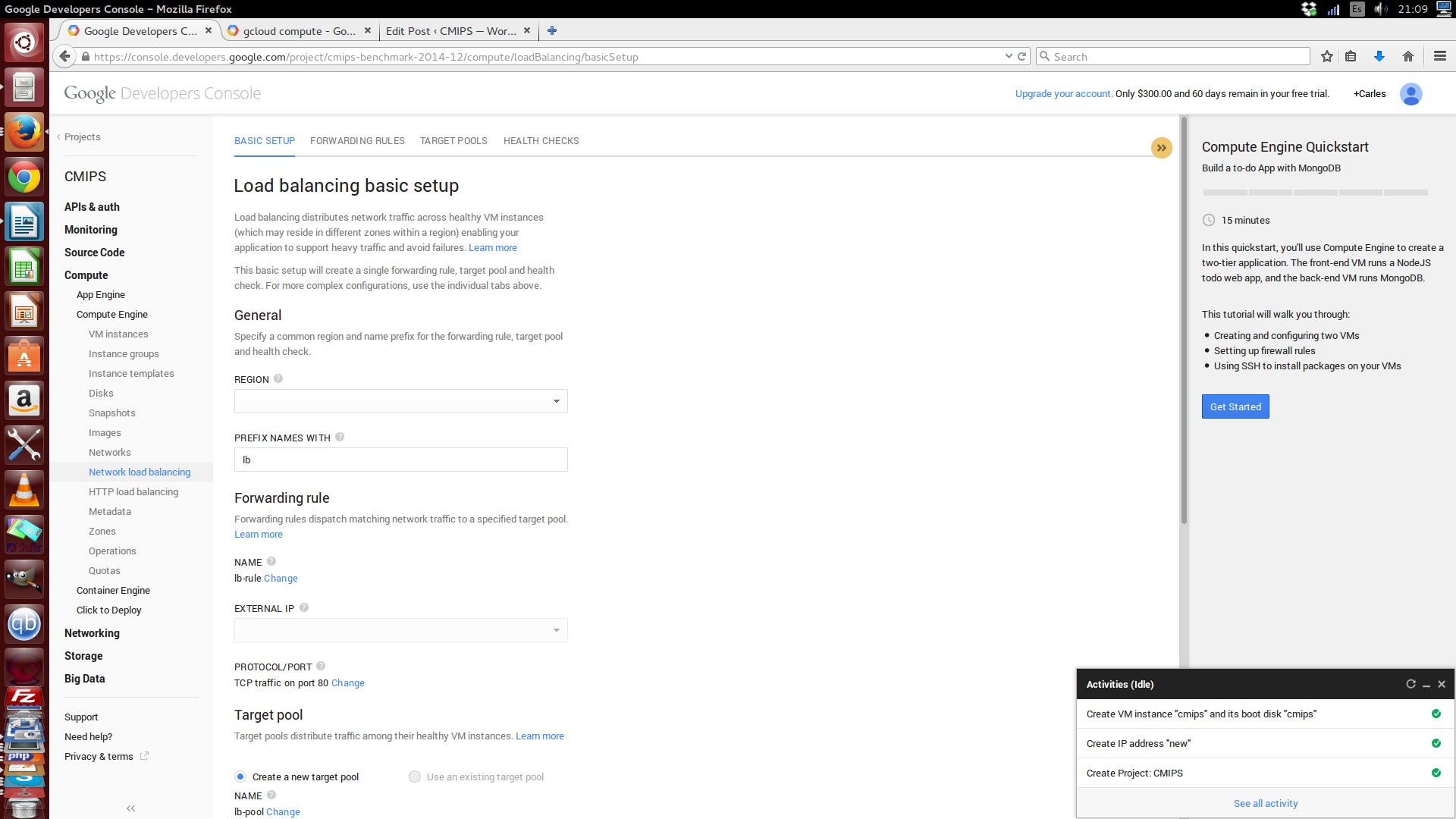
With incorporated health check to determine if a Server behind the Load Balancer is healthy or not.
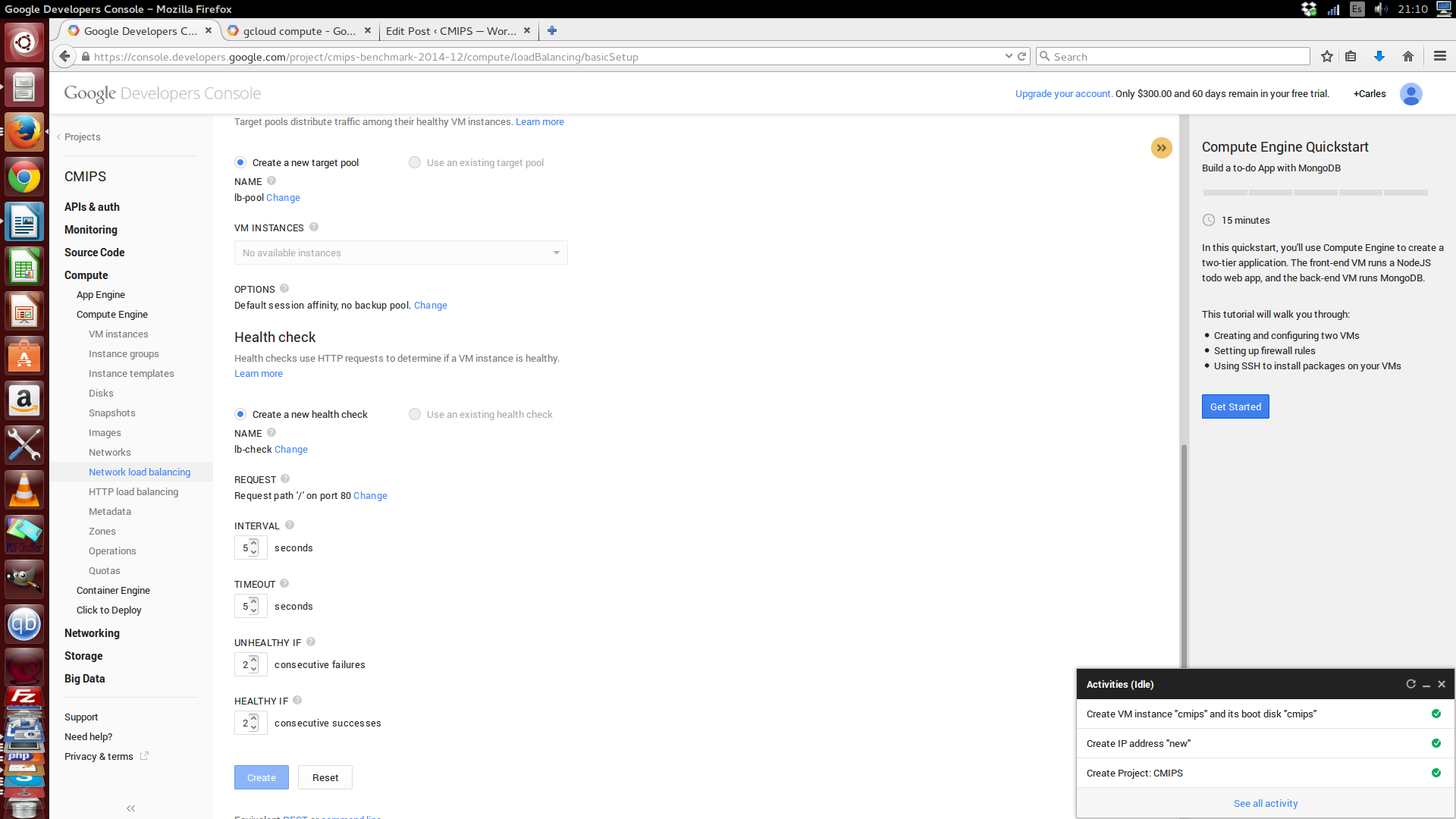
Another nice options are audit options:
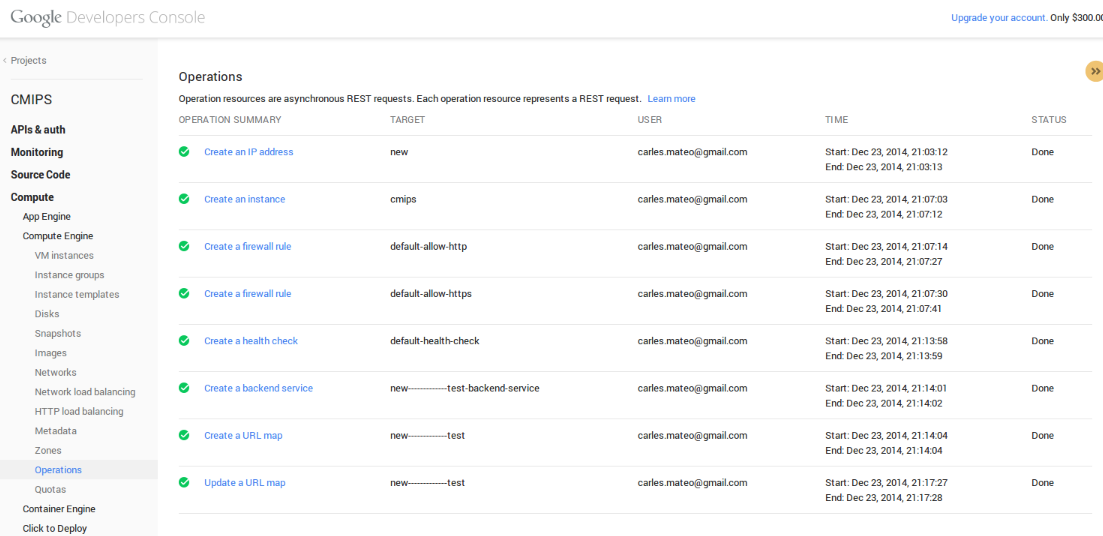
An overview of what you have in each zone:
 And very useful, to know your quota limits:
And very useful, to know your quota limits:
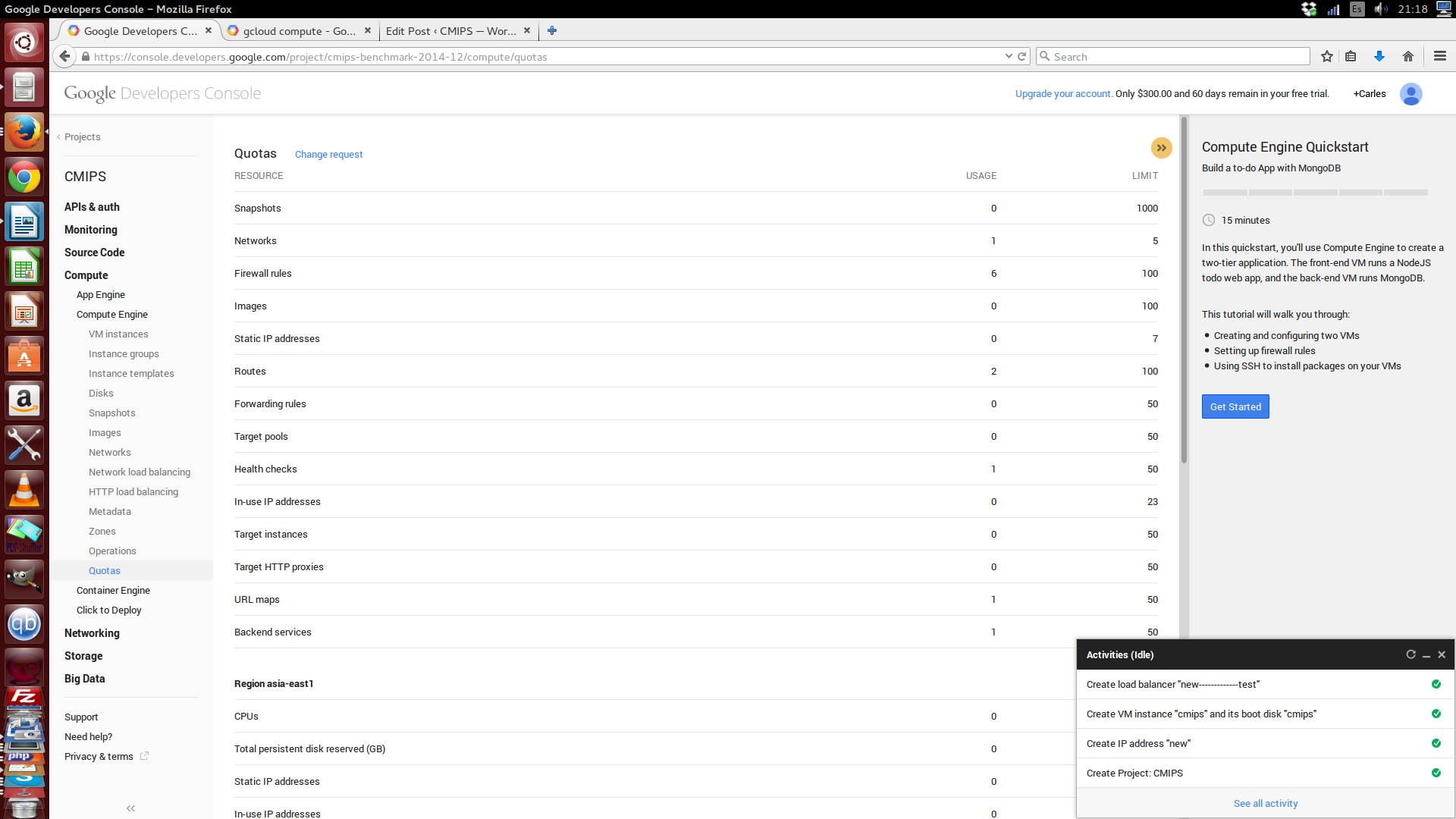
With the pertinent REST call:
{ "kind": "compute#project", "selfLink": "https://www.googleapis.com/compute/v1/projects/cmips-benchmark-2014-12", "id": "9164686651607534211", "creationTimestamp": "2014-12-23T11:55:50.451-08:00", "name": "cmips-benchmark-2014-12", "commonInstanceMetadata": { "kind": "compute#metadata", "fingerprint": "m4NhA9a-F04=" }, "quotas": [ { "metric": "SNAPSHOTS", "limit": 1000, "usage": 0 }, { "metric": "NETWORKS", "limit": 5, "usage": 1 }, { "metric": "FIREWALLS", "limit": 100, "usage": 6 }, { "metric": "IMAGES", "limit": 100, "usage": 0 }, { "metric": "STATIC_ADDRESSES", "limit": 7, "usage": 0 }, { "metric": "ROUTES", "limit": 100, "usage": 2 }, { "metric": "FORWARDING_RULES", "limit": 50, "usage": 0 }, { "metric": "TARGET_POOLS", "limit": 50, "usage": 0 }, { "metric": "HEALTH_CHECKS", "limit": 50, "usage": 1 }, { "metric": "IN_USE_ADDRESSES", "limit": 23, "usage": 0 }, { "metric": "TARGET_INSTANCES", "limit": 50, "usage": 0 }, { "metric": "TARGET_HTTP_PROXIES", "limit": 50, "usage": 0 }, { "metric": "URL_MAPS", "limit": 50, "usage": 1 }, { "metric": "BACKEND_SERVICES", "limit": 50, "usage": 1 } ] }
For the tests of performance I clone cmips v.1.0.5:
git clone https://github.com/cmips/cmips_bin
And launched several instances and did several tests.
Must say that instances start really fast. That’s a very good point when auto-scaling.
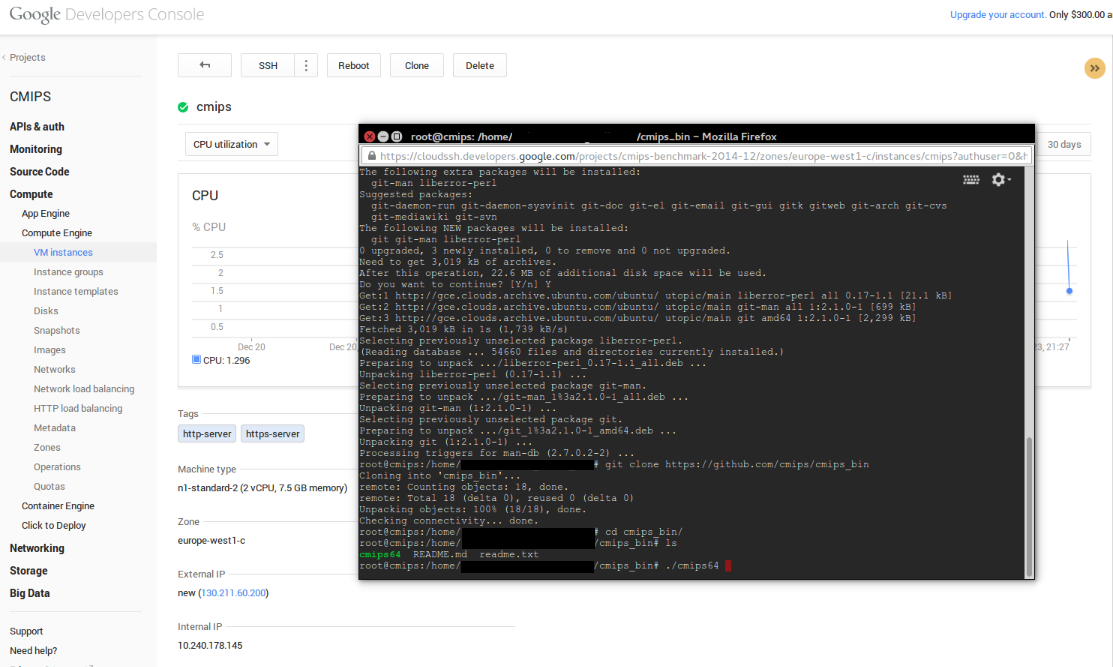
As the Free Account allowed me a max. of n1-standard-2 (2 vCPU, 7.5 GB memory) in the Zone europe-west1-c I upgraded my account and paid for the tests.
We tested these instances:
The ending number reveals the number of vCPU. In the case of the f1-micro as the CPU is shared, there is no number. The highcpu has the same CPU power than the same number of cores called standard, but the standard has more RAM.
To get a relative idea, quickly, my old laptop equipped with a dual core Intel SU4100 processor scores 460 CMIPS, and my Desktop tower, with a Intel i7-4770S and 8 cores, scores 5842 CMIPS.
Network will be dependent on the number of cores and the power of the instance as it is described on the documentation.
Egress throughput caps
Outbound or egress traffic from a virtual machine is subject to maximum network egress throughput caps. These caps are dependent on the number of cores that a virtual machine has. Each core is subject to a 2 Gbits/second cap. Each additional core increases the network cap. For example, a virtual machine with 4 cores has a network throughput cap of 2 Gbits/sec * 4 = 8 Gbits/sec network cap.
Virtual machines that have 0.5 or fewer cores, such as shared-core machine types, are treated as having 0.5 cores, and a network throughput cap of 1 Gbit/sec. All caps are meant as maximum possible performance, and not sustained performance.
Network caps are the sum of persistent disk write I/O and virtual machine network traffic. Depending on your needs, you may need to make sure your virtual machine allows for your desired persistent disk throughput. For more information, see the Persistent Disk page.
A sad note. I understand the reasons, but blocking outgoing traffic to port 25 is a deal breaker for most of the companies. The documentation tells:
Blocked traffic
Compute Engine blocks or restricts traffic through all of the following ports/protocols between the Internet and virtual machines, and between two virtual machines when traffic is addressed to their external IP addresses through these ports (this also includes load-balanced addresses).
- All outgoing traffic to port 25 (SMTP) is blocked.
- Most outgoing traffic to port 465 or 587 (SMTP over SSL) is blocked, except for known Google IP addresses.
- Traffic that uses a protocol other than TCP, UDP, and ICMP is blocked, unless explicitly allowed through Protocol Forwarding.
I tried and yes, from the instance I was unable to go to other servers outside google’s network at port 25. Is sad, because everyone needs to send email to a email server, even a WordPress send emails with the password to their users.
I asked google about that and at least offer some possible solutions:
This is a protection against spam as all mail ports are blocked.
There are two ways to handle this. One is to use one of the proxy services we list in the help. The other is to contact Google and ask for it to be unblocked.
Disk performance
Tested the disk performance using a instance: n1-highcpu-16.
As a google Performance Lead, told me, dd is not the best tool to try the performance and suggested the use of FIO:
“The problem is most I/O just gets cached in memory which makes is really hard to draw any conclusions from. I do see others using it and have been doing my best to steer them to fio. FIO is a tool that allows you the most control over the experiment. You can control queue depth size (ie number of outstanding IO’s), the size of ios, whether or not they bypass the Filesystem cache (ie direct IO), etc.”
As I explained him, and noted in other articles, I use dd for writing, with sizes of 5 GB because many hypervisors (the Software that runs on the physical server and that manages the guest instances) implement some disk cache, to offer a best performance. The hypervisor then handles when the data is effectively sent to the network Storage. As the purpose of CMIPS is offering realistic info to the Start ups about what they can expect from the Cloud providers and what not, sending 5 GB to write overruns the different layers of cache that may exist and offers a more trustworthy impression of which sustained data is really supported.
The performance for the standard disk I/O for writing was average to very good.
I got from 50 MB/s to 167 MB/s in writing, with different tests creating a 5 GB file with zeros to the disk, and 456 MB/s with 500 MB or 50 MB files. Despite it tells “standard disk” and induces one to think on magnetic disk, it looks to me like those are also SSD disks. Perhaps not so performant, but good enough. One of the reasons we do the tests with big files is to avoid fake data coming from hypervisors caching the writing to disk and reporting to the guest system that as done, and so reporting unreal speedy times for small files, and if te Architects trust those this causing problems when for real the system has to withstand a high I/O.
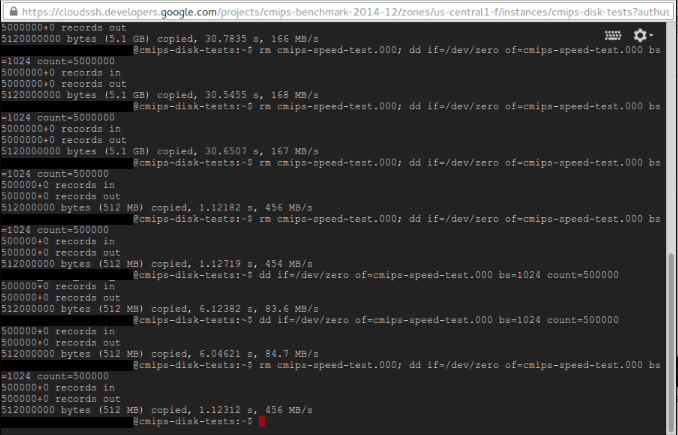
The exact command executed to test 5 GB file was:
dd if=/dev/zero of=cmips-speed-test.000 bs=1024 count=5000000
Please note: the different times when we do rm before the dd, or when we overwrite the file.
With 5 GB, 500 MB, 50 MB, 5 MB.
Then I tried the SSD and it was really disappointing.
For 5 GB I got between 24.1 MB and 32.6 MB per second, in tests another day a max of 47.2 MB/s. That was bad. Honestly, I expected much much better results and I was worried about it.
Could be because the SSD nature, TRIM Empty Blocks vs Partially Filled Blocks but many providers solve this and offer much much higher speeds. Working with network storage is always challenging at those scales but it has no sense that magnetic disks perform much more better than SSD disks.
Actually 24-47 MB/second for a SSD is unacceptable.
On my dedicated Servers with Hardware Raid 5 of SSD I get plus than 1000 MB per second in writing, and Amazon is offering around 550 MB/second in writing, no matter if I do the test with dd for 5 GB, 500 MB, 50 MB or 5 MB.
Fortunately this was only happening with the 5 GB files.
When I tested with a file with size of 500 MB or 50 MB results are good as expected, around 470-490 MB/s.
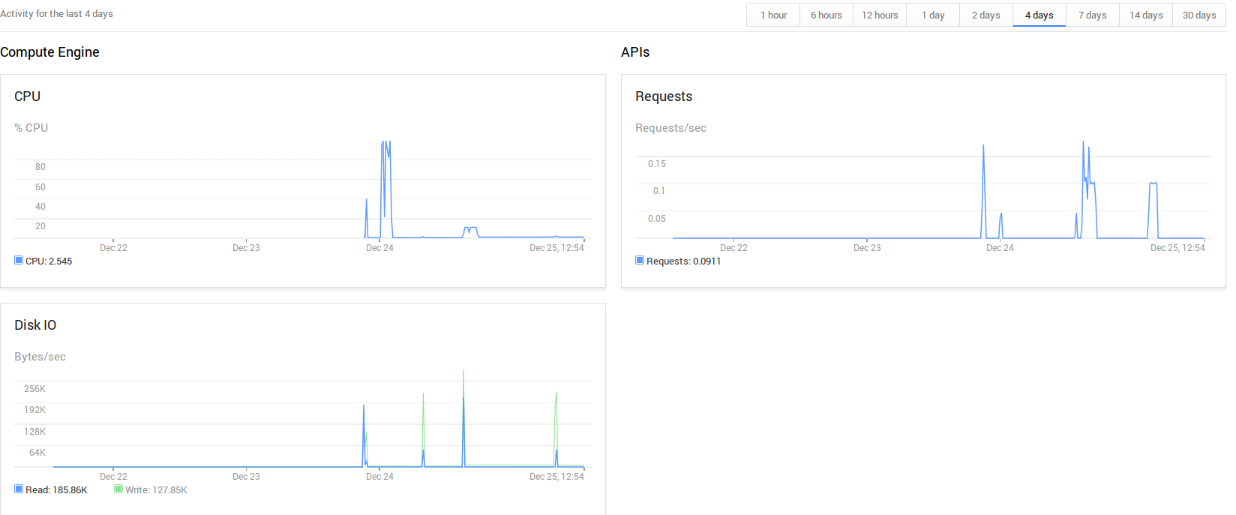
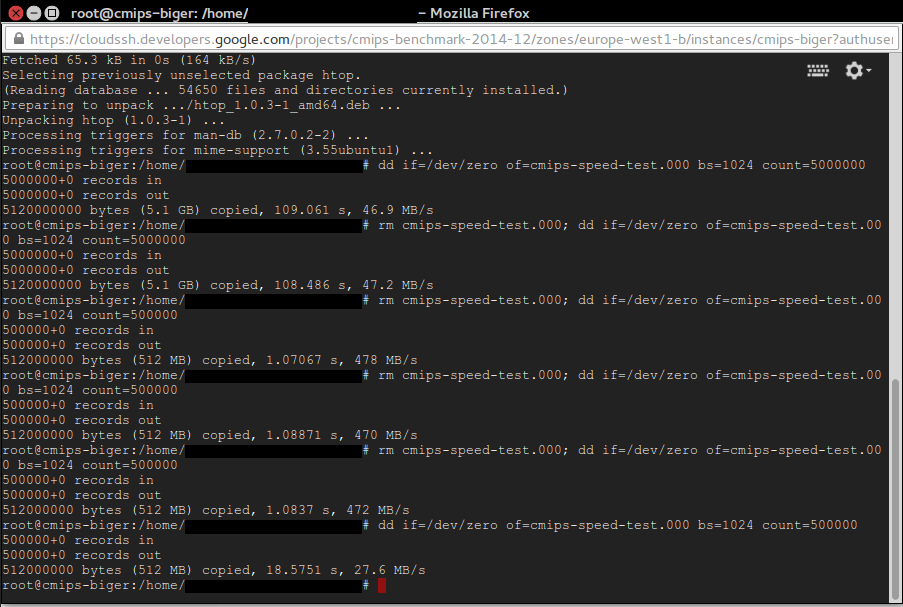
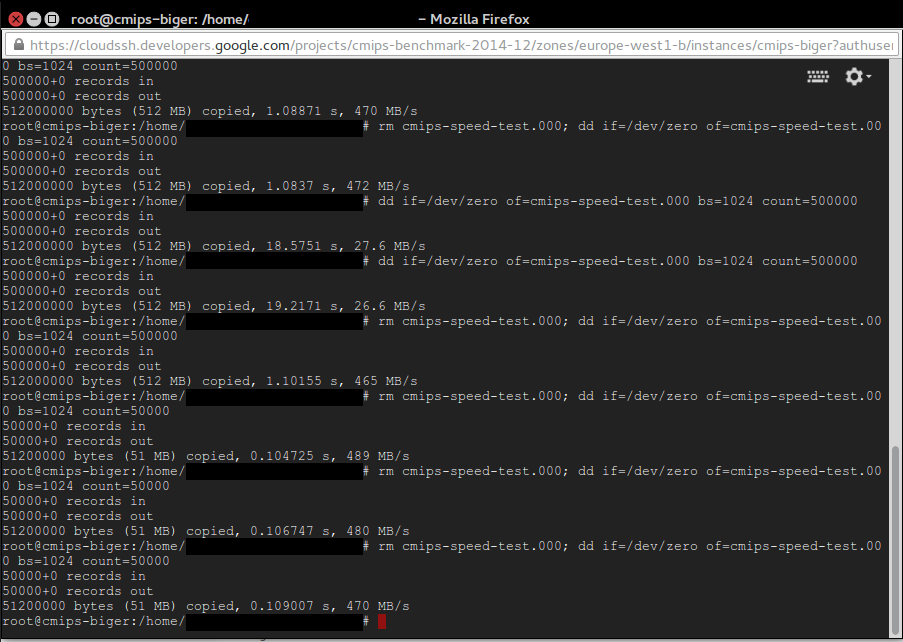
Note: To get the best result on writing tests, do not overwrite an existing file, create a new one, or delete the old one before dd. That’s because the TRIM nature of the SSD disks that makes necessary to erase old content before writing, and that is slow in terms of cycles. Some providers avoid that need, others don’t. When I do in Amazon I lost 50% of performance, so having aroung 270 MB/s instead of 500 MB/s, but when I do in Google it drops from 478 MB/s to 27.6 MB/s!. See the picture attached.
rm cmips-speed-test.000; dd if=/dev/zero of=cmips-speed-test.000 bs=1024 count=5000000
 We also discussed this with the wonderful Engineering crew at google, and they explained me that the IO performance is provisioned according to the size of the disk of the instance. They also referred me to the documentation about disk, that is really excellent. You must read it to fully understand the google Cloud potential, as it also offers burst, for example for instances with small disk and few IO, but that will benefit from those punctual needs to I/O and burst the speed.
We also discussed this with the wonderful Engineering crew at google, and they explained me that the IO performance is provisioned according to the size of the disk of the instance. They also referred me to the documentation about disk, that is really excellent. You must read it to fully understand the google Cloud potential, as it also offers burst, for example for instances with small disk and few IO, but that will benefit from those punctual needs to I/O and burst the speed.
From the docs, in order to try to estimate predictable performance results:
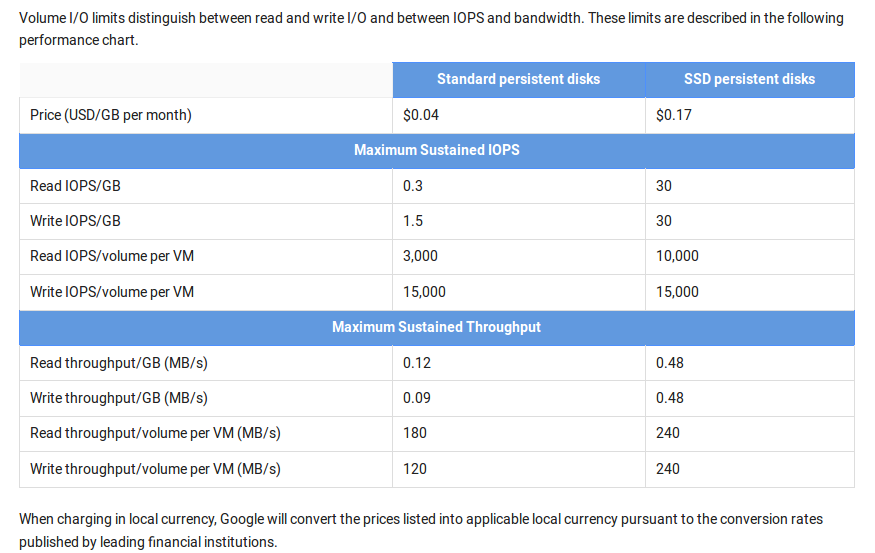
Performance depends on I/O pattern, volume size, and instance type.
As an example of how you can use the performance chart to determine the disk volume you want, consider that a 500GB standard persistent disk will give you:
- (0.3 x 500) = 150 small random reads
- (1.5 x 500) = 750 small random writes
- (0.12 x 500) = 60 MB/s of large sequential reads
- (0.09 x 500) = 45 MB/s of large sequential writes
IOPS numbers for SSD persistent disks are published with the assumption of up to 16K I/O operation size.
Compute Engine assumes that each I/O operation will be less than or equal to 16KB in size. If your I/O operation is larger than 16KB, the number of IOPS will be proportionally smaller. For example, for a 200GB SSD persistent disk, you can perform (30 * 200) = 6,000 16KB IOPS or 1,500 64KB IOPS.
Conversely, the throughput you experience decreases if your I/O operation is less than 4KB. The same 200GB volume can perform throughput of 96 MB/s of 16 KB I/Os or 24 MB/s of 4KB I/Os.
To be fair in my tests the disk was the smaller possible to hold the Ubuntu image and to generate the 5 GB files, so around 8 GB.
Also the size of the block size being written is important. In my tests I used 1 KB (bs=1024), that is typical for logs. Other options for typical programs are 4 KB or 8 KB, 16 KB. The tests on disk performance requires a set of own tests and articles. As the scenario can change completely using other software like Hadoop that uses 64 MB Blocks or bigger, and writes large chunks.
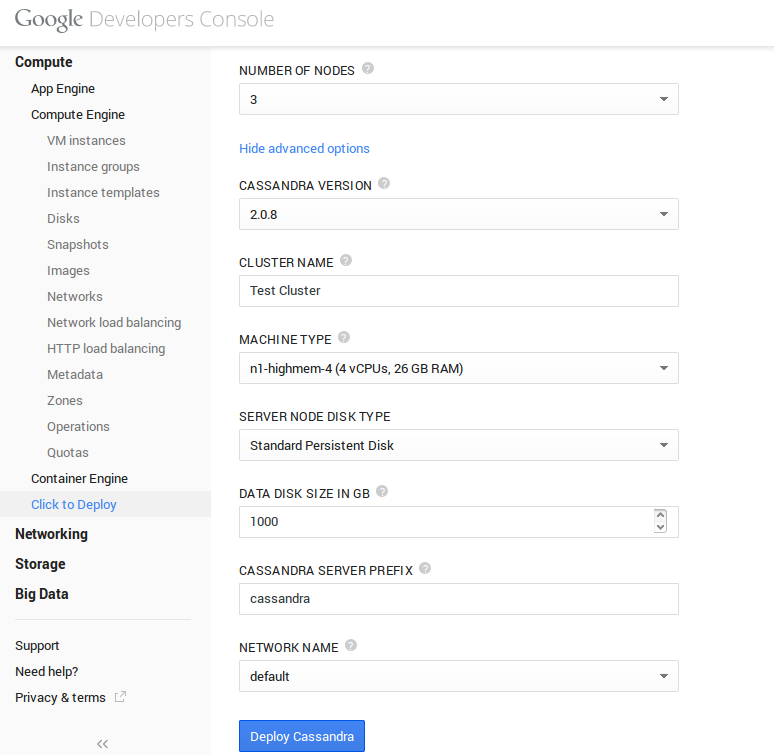
Also, as indicated before, network caps are applied for Storage + Network traffic, so if you deal with heavy traffic, or plan to serve video on demand, you’ll benefice from launching less bigger instances rather than much smaller instances. This is very important to take into consideration for Cassandra clusters, for example.
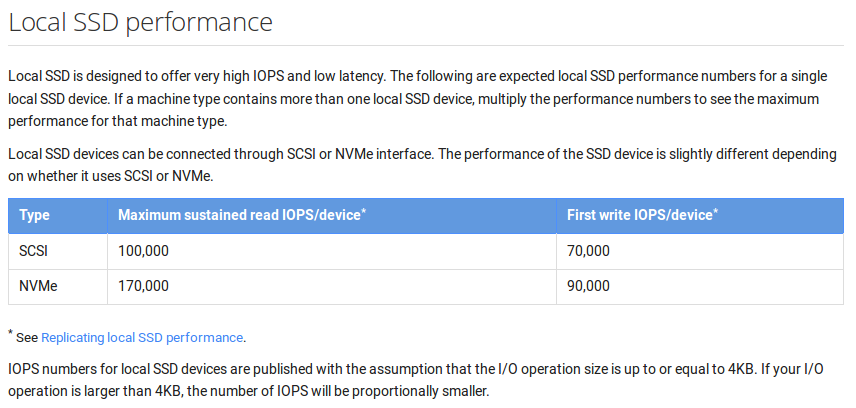
Just after I finished this article I read by RSS that 7 hours ago new SSD local storage has been released for Google cloud. Local SSD is available for gcloud command line tool version 0.9.37 and higher.
While I was going to publish the article a new service, in beta, has just been presented: the google Cloud Monitoring.
I love that it can send you alerts from SMS. Also email, PagerDuty, HipChat. It claims to “provide insight into many common open source servers with minimal configuration. Understand trends unique to your Cassandra cluster or Nginx servers.”
Thanks to Anthony F. Voellm for the interesting discussion on google performance and tools, and for putting all his Team and his colleagues into solving the most cutting edge doubts I raised, as well as for sharing with his coworkers, Product Managers and other Teams this analysis, and the niceness about having this feedback.
Past yesterday, 12th Jan 2015, Amazon announced the launching of the C4 instances.
Those are the most powerful instances from Amazon to the date.
The new C4 instances are based on the Intel Xeon E5-2666 v3 processors, code name Haswell.
Nowadays CPU’s have turbo and are able to run at more speed depending on several factors, like temperature, power consumption and heat generation (in some cases if two cores are used and the rest not, those two core can run faster), that’s why cmips stresses all the cores and 100% of the capacity of the Servers.
Those processors run at a base speed of 2.9 GHz, and can achieve clock up to 3.5 GHz speeds with Intel® Turbo Boost (complete specifications are available here).
As a result of that CMIPS can have little variation from one test to another, if the difference is small, we get the higher value.
turbostat command is provided to be able to manually try to set speeds of the cores.
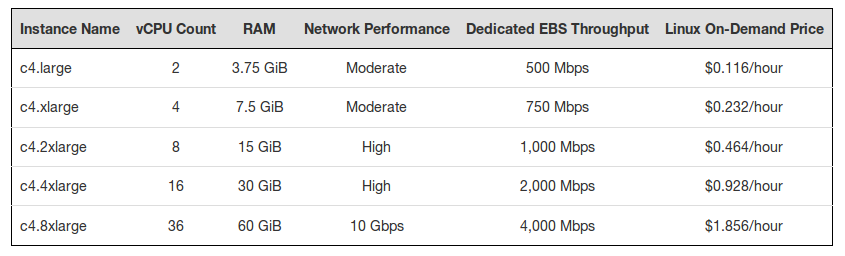 (prices are a bit different in some zones, those are for US and EU)
(prices are a bit different in some zones, those are for US and EU)
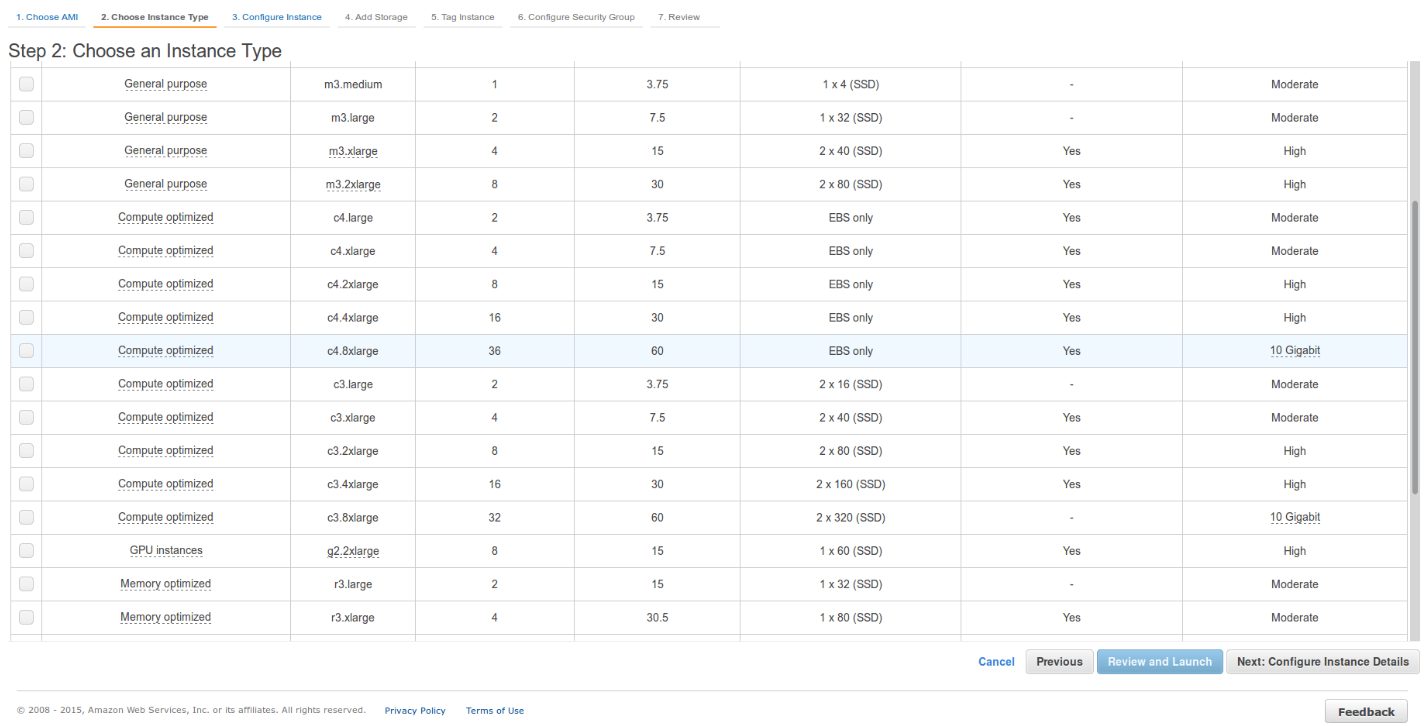
We tested the c4.8xlarge, to see the top scale.
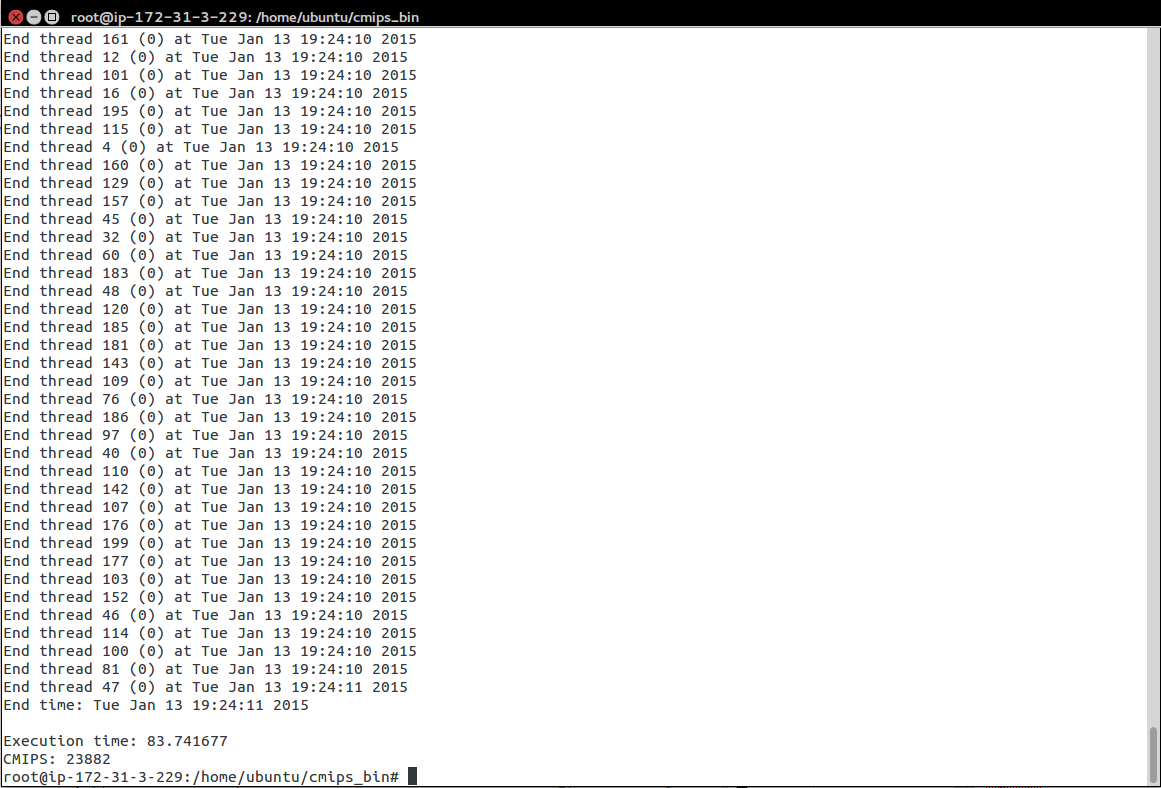
In our tests, the c4.8xlarge achieved 23,882 CMIPS.
That’s much much higher than the c3.8xlarge (that has 32 vCPU) that scores 17,476 CMIPS (CPU Intel(R) Xeon(R) CPU E5-2680 v2 @ 2.80GHz), with a similar price.
The results show that the c4.8xlarge is the most powerful instance we have seen to the date, and the number one in our rankings, only beaten by the CloudSigma‘s 4 x Intel Xeon E5-4657L v.2 multiprocessor dedicated Server provided for comparison with fullstack physical servers (with 48 cores and a score of 28,753 CMIPS).
This is the report from cpuinfo for one of the cores:
processor : 35 vendor_id : GenuineIntel cpu family : 6 model : 63 model name : Intel(R) Xeon(R) CPU E5-2666 v3 @ 2.90GHz stepping : 2 microcode : 0x25 cpu MHz : 1200.000 cache size : 25600 KB physical id : 1 siblings : 18 core id : 8 cpu cores : 9 apicid : 49 initial apicid : 49 fpu : yes fpu_exception : yes cpuid level : 13 wp : yes flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ht syscall nx rdtscp lm constant_tsc rep_good nopl xtopology nonstop_tsc aperfmperf eagerfpu pni pclmulqdq monitor est ssse3 fma cx16 pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand hypervisor lahf_lm abm ida xsaveopt fsgsbase bmi1 avx2 smep bmi2 erms invpcid bogomips : 5861.99 clflush size : 64 cache_alignment : 64 address sizes : 46 bits physical, 48 bits virtual
The tests were run in a Ubuntu 14.04 Server 64 bits (vps, hvm virtualization), in the zone Ireland and the storage type was gp2 (General Purpose SSD).
It is a instance equipped with 10Gbit, but I’m really shocked about storage’s performance, as with our standard test of dd on 5 GB file on the default filesystem (/dev/sda1), we got poor result:
dd if=/dev/zero of=cmips-speed-test.000 bs=1024 count=5000000
root@ip-172-31-3-229:/home/ubuntu/cmips_bin# dd if=/dev/zero of=cmips-speed-test.000 bs=1024 count=5000000 5000000+0 records in 5000000+0 records out 5120000000 bytes (5.1 GB) copied, 41.404 s, 124 MB/s dd if=/dev/zero of=cmips-speed-test.000 bs=1024 count=5000000 5000000+0 records in 5000000+0 records out 5120000000 bytes (5.1 GB) copied, 49.091 s, 104 MB/s root@ip-172-31-3-229:/home/ubuntu/cmips_bin# rm cmips-speed-test.000; dd if=/dev/zero of=cmips-speed-test.000 bs=1024 count=5000000 5000000+0 records in 5000000+0 records out 5120000000 bytes (5.1 GB) copied, 34.3242 s, 149 MB/s
As you saw, the throughput of the disks creating at 5GB file is really disappointing, specially taking in count that we are talking about SSD, that EBS Optimization is enabled by default and that “this feature provides 500 Mbps to 4,000 Mbps of dedicated throughput to EBS above and beyond the general purpose network throughput provided to the instance”. In other tests, with other instances from Amazon we have achieved 490 MB/second, so I’ve checked the documentation and I found that necessary steps may be necessary to benefit from enhanced network performance.
Also the max. throughput published in the documentation doesn’t match my previous results (much higher) and with the information published in the Amazon’s blog about “[…]500 Mbps to 4,000 Mbps[…]”. As publishing this article I tried with one of my running c3.4xlarge and got 201 MB/second (/dev/xvda1).
As the C4 are very new perhaps Amazon are still adjusting and fine-tuning performance.
I’m asking Amazon about that.
Update:
On 15th January I asked to Amazon ec2-c4-feedback [at] amazon.com:
Hi,
I’m Carles Mateo, CTO of several Start ups, and founder of cmips.net.
At cmips we benchmark the performance of the instances of the main Cloud Providers.
I just benchmarked your new c4.8xlarge and published an article http://www.cmips.net/2015/01/
I launched a Ubuntu 14.04 Server 64 bit, I did some basic storage performance tests that I do as standard always, and I got very disappointed about the performance and have some doubts.
I did:
dd if=/dev/zero of=cmips-speed-test.000 bs=1024 count=5000000
Obtaining:
root@ip-172-31-3-229:/home/
So between, 104 MB/s and 149 MB/s.
(The rm before the dd is for the TRIM SSD issue)
As with Amazon’s much more smaller machines I’ve obtained throughput around 490 MB/s with 5 GB files my questions are:
1) I got 490 MB/s with other instances, with Ubuntu as well, without EBS Optimisation and without any special tunning.
According to your page http://docs.aws.amazon.com/
1.1) Is that right?. Should I follow the steps to benefit from Enhanced Network on the VPC?
1.2) Does that Enhanced Network benefit to Storage also or is only for general networking (not storage) like Apache, ping, etc…?
2) Your page http://docs.aws.amazon.com/
2.1) Does that means the limit of the bandwidth or has to be added to the EBS standard throughput?
2.2) The document says that for a c3.4xlarge the maximum is 250 MB/s, but doing a dd on one of those I got 320 MB/s.
5000000+0 records in
5000000+0 records out
5120000000 bytes (5.1 GB) copied, 16.0044 s, 320 MB/s
How is that possible?
3) Your announcement of the c4 instances tells:
“As I noted in my original post, EBS Optimization is enabled by default for all C4 instance sizes. This feature provides 500 Mbps to 4,000 Mbps of dedicated throughput to EBS above and beyond the general purpose network”
3.1) 4,000 Mbps means 500 MB/s above and beyond the general purpose network, but your document http://docs.aws.amazon.com/
3.2) Are network and storage network sharing the same cables and infrastructure or are different ethernets/switches, etc…?
4) Do you implement any type of Storage cache at hypervisor level? And at Storage level?
5) is dd from /dev/zero with big files a good way to get the idea of the available bandwidth / throughput?. Do you recommend other mechanisms for getting the idea of the performance?.
Thanks.
Best,
Carles Mateo
On 19th January I got reply from Amazon:
Hi Carles,
Thanks for your feedback on C4!
Regarding (1), we currently expect that a single EBS GP2 volume can burst up to 128 MBps[1]. I believe the variation in your results is because the command you are using writes data out to the page cache. You are writing out enough data to exhaust the page cache so I believe the numbers you are getting are roughly accurate however for more consistent results, we would recommend using a tool like fio[2].
Indeed, the Instance Storage on some previous generation platforms can achieve higher results today but we announced improvements to EBS which you may be interested in at re:Invent[3].
Most popular AMIs enable Enhanced Networking by default and it does not have an impact on EBS performance.
The EBS Optimized limits are culmulative for all volumes, not for individual volumes.
Unfortunately, we cannot provide details about our underlying storage layer but if you have other questions about C4, I would be happy to answer them.
Thanks again for taking the time to provide feedback!
[1] http://docs.aws.amazon.com/
[2] http://docs.aws.amazon.com/
[3] https://aws.amazon.com/blogs/
Regards,
We are proud to release a new version of CMIPS.
This new release improves:
As most powerful Commodity Servers are approaching to 100 cores we doubled the number of concurrent threads for the tests. Any Server bellow 200 cores can be tested.
The CMIPS score scale compatibility is maintained, so values are consistent with older CMIPS versions, but times for the tests are doubled.
The new information provided at the start of the cmips binary (also written to the log) includes the number of max-threads configured in the system and the CPU info found on /proc/cpuinfo.
Example:
CMIPS V1.0.5 by Carles Mateo - www.carlesmateo.com Max threads in the system: 505827 (from /proc/sys/kernel/threads-max) /proc/cpuinfo processor : 0 vendor_id : GenuineIntel cpu family : 6 model : 60 model name : Intel(R) Core(TM) i7-4770S CPU @ 3.10GHz stepping : 3 microcode : 0x9 cpu MHz : 800.000 cache size : 8192 KB physical id : 0 siblings : 8 core id : 0 cpu cores : 4 apicid : 0 initial apicid : 0 fpu : yes fpu_exception : yes cpuid level : 13 wp : yes flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc aperfmperf eagerfpu pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 fma cx16 xtpr pdcm pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm ida arat epb xsaveopt pln pts dtherm tpr_shadow vnmi flexpriority ept vpid fsgsbase tsc_adjust bmi1 hle avx2 smep bmi2 erms invpcid rtm bogomips : 6385.11 clflush size : 64 cache_alignment : 64 address sizes : 39 bits physical, 48 bits virtual power management:
Source code can be downloaded from:
https://github.com/cmips/cmips
It is ready to be used with NetBeans 8.
And binaries only:
I want to add some new benchmarks of a dedicated Server, to compare with the cloud instances’ power.
Thanks to my friends at CloudSigma that were so kind to invite me to their offices, and provided me with everything I needed and gave me total access to this powerful server for the tests.
The Server is a four CPU Intel Xeon, concretely the CPUs are the new Intel® Xeon® Processor E5-4657L v2 (30M Cache, 2.40 GHz) , released on the first Quarter of 2014.
This CPU has 12 core (#24 Threads), and performs from 2.4 Ghz to 2.9 Ghz with the Turbo, and has 30 MB of Intel Smart Cache and Max TDP is only 115W.
So this Server has a total of 12 core x 4 CPUs = 48 cores.
 The Server was equipped with 384 GB of RAM, SSD disks and fibre cards, and I analyzed more performance aspects, but this is irrelevant for the CPU speed tests presented here.
The Server was equipped with 384 GB of RAM, SSD disks and fibre cards, and I analyzed more performance aspects, but this is irrelevant for the CPU speed tests presented here.
In the several tests this Server achieved the astonishing score of 28,753 CMIPS, and the tests took 34.7779 seconds, smashing the previous records.
This is the best score achieved so far, and the most powerful dedicated Server evaluated to the date. Comparing the CMIPS score, it is much much more powerful than the Amazon cluster instance c3.8xlarge, the most powerful instance tested to the date. And it doesn’t require any special cluster’s kernel.
If you have a main Master MySql Server or other CPU hungry service you would probably want to have one of these as dedicated Server, and having your FrontEnd Servers in the Cloud, as instances, auto-scaling, connecting to this beast in an hybrid configuration.
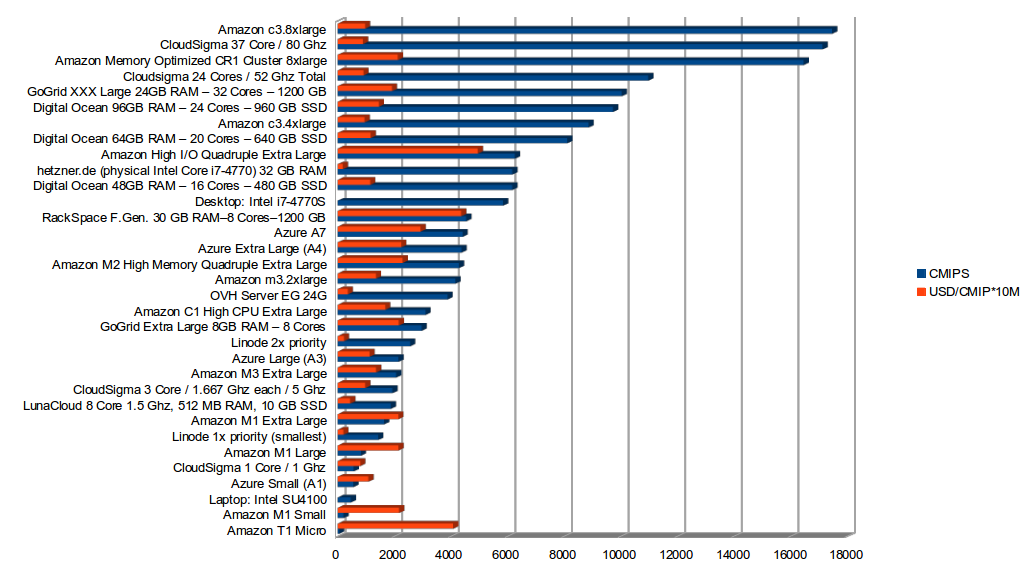
Blue bar: CMIPS – More is better (Performance)
Red bar: CUPS – Less is cheaper (Cost Unit Process)
Amazon has reduced up to 40% their prices, with effect today 1st April.
Note: I noticed t1.micro, hi1.4xlarge and cr1.8xlarge prices didn’t change.
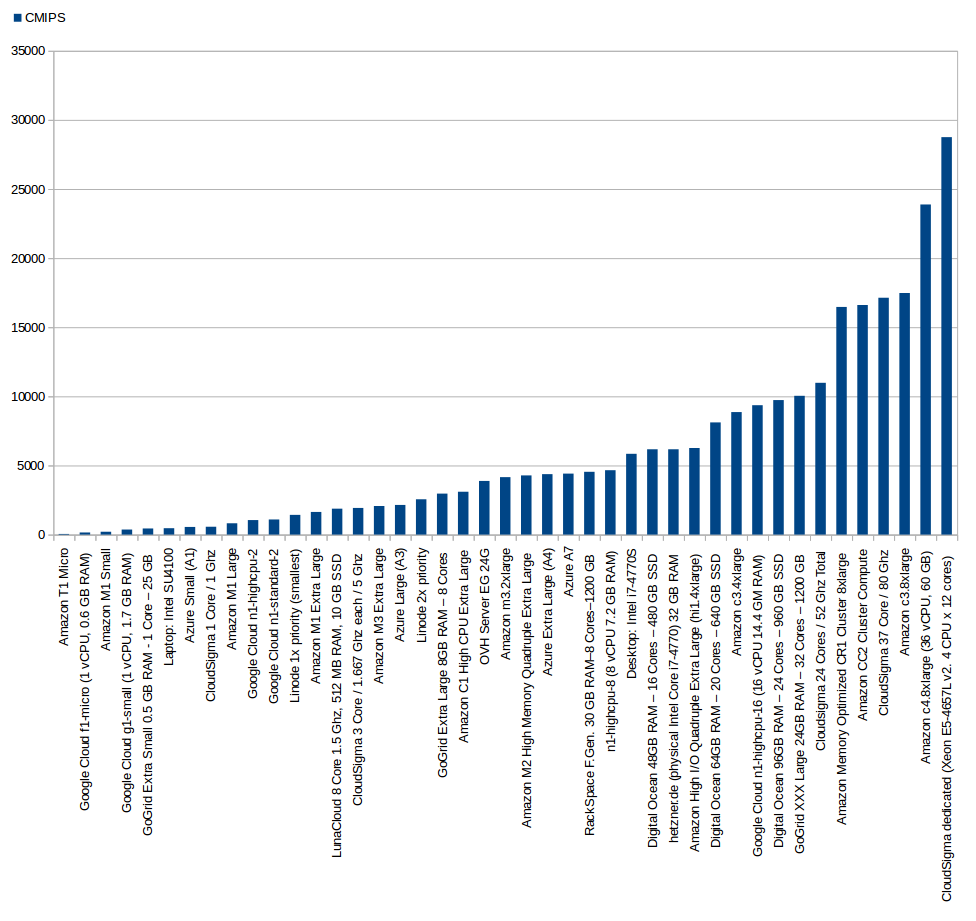
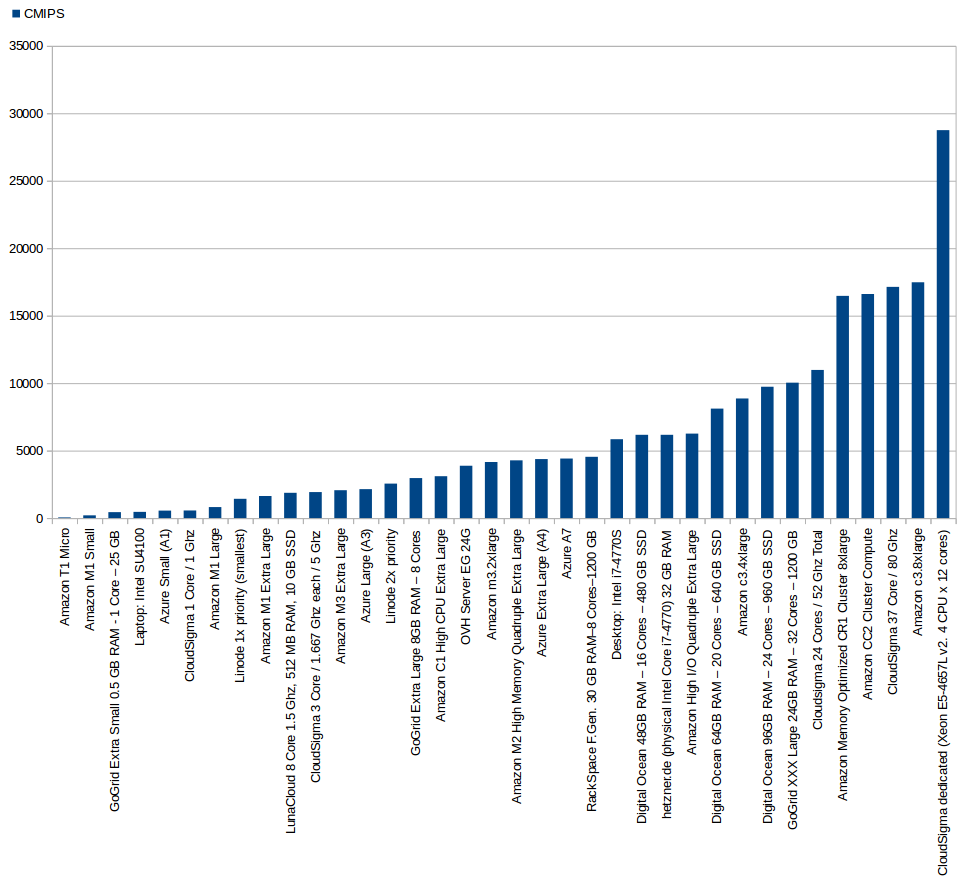
Detailed results, with pricing update. More CMIPS score is better:
| Type of Service | Provider | Name of the product | Codename | Zone | Processor | Ghz Processor | Cores (from htop) | RAM (GB) | Os tested | CMIPS | Execution time (seconds) | USD /hour | USD /month |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Cloud | T1 Micro | t1.micro | US East | Intel Xeon E5-2650 | 2 | 1 | 0.613 | Ubuntu Server 13.04 64 bits | 49 | 20,036.7s | $0.02 | $14.40 | |
| Cloud | M1 Small | m1.small | US East | Intel Xeon E5-2650 | 2 | 1 | 1.6 | Ubuntu Server 13.04 64 bits | 203 | 4,909.89s | $0.044 | $31.68 | |
| Cloud | GoGrid | Extra Small (512 MB) | Extra Small | US-East-1 | Intel Xeon E5520 | 2.27 | 1 | 0.5 | Ubuntu Server 12.04 64 bits | 441 | 2,265.14s | $0.04 | $18.13 |
| Physical (laptop) | Intel SU4100 | 1.4 | 2 | 4 | Ubuntu Desktop 12.04 64 bits | 460 | 2,170.32s | ||||||
| Cloud | 1 Core / 1 Ghz | 1 Core / 1 Ghz | Zurich (Europe) | Amd Opteron 6380 | 2.5 Ghz to 3.4 Ghz with Turbo | 1 | 1 | Ubuntu Server 12.04.3 64 bits | 565 to 440 | 1,800s | $0.04475 | $32,22 | |
| Cloud | M1 Large | m1.large | US East | Intel Xeon E5-2650 | 2 | 2 | 7.5 | Ubuntu 13.04 64 bits | 817 | 1,223.67s | $0.175 | $126 | |
| Cloud | Linode | 1x priority (smallest) | 1x priority | London | Intel Xeon E5-2670 | 2.6 | 8 | 1 | Ubuntu Server 12.04 64 bits | 1,427 | 700.348s | n/a | $20 |
| Cloud | M1 Extra Large | m1.xlarge | US East | Intel Xeon E5-2650 | 2 | 4 | 15 | Ubuntu 13.04 64 bits | 1,635 | 606.6s | $0.35 | $252 | |
| Cloud | LunaCloud | 8 Core 1.5 Ghz, 512 MB RAM, 10 GB SSD | CH | 1.5 | 8 | 0.5 | Ubuntu 13.10 64 bits | 1,859 | 537.64s | $0.0187 | $58.87 | ||
| Cloud | 3 Core / 1,667 Ghz each / 5 Ghz Total | 3 Core / 1,667 Ghz each / 5 Ghz Total | Zurich (Europe) | Amd Opteron 6380 | 2.5 Ghz to 3.4 Ghz with Turbo | 3 | 1 | Ubuntu Server 13.10 64 bits | 1928 to 1675 | 518.64s | $0.1875 | $135 | |
| Cloud | M3 Extra Large | m3.xlarge | US East | Intel Xeon E5-2670 | 2.6 | 4 | 15 | Ubuntu 13.04 64 bits | 2,065 | 484.1s | $0.28 | $201,60 | |
| Cloud | Linode | 2x priority | 2x priority | Dallas, Texas, US | Intel Xeon E5-2670 | 2.6 | 2 | Ubuntu Server 12.04 64 bits | 2,556 | 391.19s | n/a | $40 | |
| Cloud | GoGrid | Extra Large (8GB) | Extra Large | US-East-1 | Intel Xeon E5520 | 2.27 | 8 | 8 | Ubuntu Server 12.04 64 bits | 2,965 | 327.226s | $0.64 | $290 |
| Cloud | C1 High CPU Extra Large | c1.xlarge | US East | Intel Xeon E5506 | 2.13 | 8 | 7 | Ubuntu Server 13.04 64 bits | 3,101 | 322.39s | $0.52 | $374.40 | |
| Dedicated | OVH | Server EG 24G | EG 24G | France | Intel Xeon W3530 | 2.8 | 8 | 24 | Ubuntu Server 13.04 64 bits | 3,881 | 257.01s | n/a | $99 |
| Cloud | M3 2x Extra Large | m3.2xlarge | US East | Intel Xeon E5-2670 v2 | 2.5 | 8 | 30 | Ubuntu Server 13.04 64 bits | 4,156 | 240.597s | $0.56 | $403.2 | |
| Cloud | M2 High Memory Quadruple Extra Large | m2.4xlarge | US East | Intel Xeon E5-2665 | 2.4 | 8 | 68.4 | Ubuntu Server 13.04 64 bits | 4,281 | 233.545s | $0.98 | $706.60 | |
| Cloud | Rackspace | RackSpace First Generation 30 GB RAM – 8 Cores – 1200 GB | US | Quad-Core AMD Opteron(tm) Processor 2374 HE | 2.2 | 8 | 30 | Ubuntu Server 12.04 64 bits | 4,539 | 220.89s | $1.98 | $1,425.60 | |
| Physical (desktop workstation) | Intel Core i7-4770S | 3.1 (to 3.9 with turbo) | 8 | 32 | Ubuntu Desktop 13.04 64 bits | 5,842 | 171.56s | ||||||
| Cloud | Digital Ocean | Digital Ocean 48GB RAM – 16 Cores – 480 GB SSD | Amsterdam 1 | QEMU Virtual CPU version 1.0 | 16 | 48 | Ubuntu Server 13.04 64 bits | 6,172 | 161.996s | $0.705 | $480 | ||
| Cloud | High I/O Quadruple Extra Large | hi1.4xlarge | US East | Intel Xeon E5620 | 2.4 | 16 | 60.5 | Ubuntu Server 13.04 64 bits | 6,263 | 159.65s | $3.1 | $2,232 | |
| Cloud | Digital Ocean | Digital Ocean 64GB RAM – 20 Cores – 640 GB SSD | Amsterdam 1 | QEMU Virtual CPU version 1.0 | 20 | 64 | Ubuntu Server 13.04 64 bits | 8,116 | 123.2s | $0.941 | $640 | ||
| Cloud | Compute Optimized C3 4x Large | c3.4xlarge | US East | Intel Xeon E5-2680 v2 | 2.8 | 16 | 30 | Ubuntu Server 13.04 64 bits | 8,865 | 112.8s | $0.84 | $604.80 | |
| Cloud | Digital Ocean | Digital Ocean 96GB RAM – 24 Cores – 960 GB SSD | New York 2 | QEMU Virtual CPU version 1.0 | 24 | 96 | Ubuntu Server 13.04 64 bits | 9,733 | 102.743s | $1.411 | $960 | ||
| Cloud | GoGrid | XXX Large (24GB) | XXX Large | US-East-1 | Intel Xeon X5650 | 2.67 | 32 | 24 | Ubuntu Server 12.04 64 bits | 10,037 | 99.622s | $1.92 | $870 |
| Cloud | 24 Core / 52 Ghz Total | 24 Core / 52 Ghz Total | Zurich (Europe) | Amd Opteron 6380 | 2.5 Ghz to 3.4 Ghz with Turbo | 24 | 1 | Ubuntu Server 13.10 64 bits | 10979 to 8530 | 98s | $0.9975 | $718.20 | |
| Cloud | Memory Optimized CR1 Cluster 8xlarge | cr1.8xlarge | US East | Intel Xeon E5-2670 | 2.6 | 32 | 244 | Ubuntu Server 13.04 64 bits for HVM instances (Cluster) | 16,468 | 60.721s | $3.5 | $2,520 | |
| Cloud | Compute Optimized CC2 Cluster 8xlarge | cc2.8xlarge | US East | Intel Xeon E5-2670 | 2.6 | 32 | 60.5 | Ubuntu Server 13.04 64 bits for HVM instances (Cluster) | 16,608 | 60.21s | $2 | $1,440 | |
| Cloud | 37 Core / 2.16 Ghz each / 80 Ghz Total | 37 Core / 2.16 Ghz each / 80 Ghz Total | Zurich (Europe) | Amd Opteron 6380 | 2.5 Ghz to 3.4 Ghz with Turbo | 37 | 1 | Ubuntu Server 13.10 64 bits | 17136 to 8539 | 58s | $1.5195 | $1,094.10 | |
| Cloud | Compute Optimized C3 8xlarge | c3.8xlarge | US East | Intel Xeon E5-2680 | 2.8 | 32 | 60 | Ubuntu Server 13.10 64 bits for HVM instances (Cluster) | 17,476 | 57.21s | $1.68 | $1,209.6 |
The source code for CMIPS v. 1.0.4 has been released as Open Source.
After several petitions we decided to make it available immediately.
You can git clone it:
git clone https://github.com/cmips/cmips
This downloads the main.cpp, the cmips binary compiled for 64 bit, and project files for working with NetBeans IDE 7.3.1.
I’ve been requested to explain how CMIPS works. Here I explain the basic mechanics of the source code for the CPU and RAM speed benchmarks.
Cmips uses a lot of my knowledge on computers, architecture, virtualization and assembler to prevent the hypervisors from devising the results, and providing fake data.
So at the end the program is a very precise one, concentrating into doing its jobs the best way possible.
It uses a very small binary file and really few amount of RAM to prevent the Host hypervisor from improving or worse the pure results (some providers allow the tenants to use more total RAM than the host server actually have, as many times only a part of the RAM assigned to the instances is really used, and uses swap the same way a computer does if RAM is really used).
Basically it calculates the CPU speed, by doing simple calculations involving the hardware registers and the read and write access to memory speed.
For the writings to the memory only one byte is written, and different, to minimize the hardware and software caches optimizations.
The operations are the simplest, the most close to assembler basic functions.
Operations are:
So there are no callings to the Operating System that can be tweaked by the Hypervisor / guest tools or containers.
Finally cmips launches 100 threads (void *t_calculations(void *param)) at the same time to stress all the cores available, and provide a real benchmark on the independent CPU power of the public instance (some host servers isolate or share resources more than others, so cmips claims all the resources to get the real picture of performance provided).
When we benchmark an instance, we block the firewall to prevent incoming petitions from wasting resources and we launch cmips several times, one time after the other, on the same instance to be sure that the results are consistent and reliable.
Netbeans is used as IDE for the cmips source code. (For my Linux C++ GUI apps I use Qt Creator)
That’s the basic code in C++
Using those libraries:
#include <cstdlib> #include <iostream> #include <stdio.h> #include <stdlib.h> #include <pthread.h> #include <fstream> #include <sstream> #include <cstring> #include <sys/time.h> #include <ctime> using namespace std;
So we link the program with the standard Posix thread library:
-o ${CND_DISTDIR}/${CND_CONF}/${CND_PLATFORM}/cmips -lpthread
Some global variables:
typedef unsigned long long timestamp_t; char s_cmips[50] = "CMIPS V.1.0.3 by Carles Mateo www.carlesmateo.com"; char s_tmp_copy[1]; int i_max_threads = 100; int i_finished_threads = 0; int i_loop1 = 0; int i_loop_max = 32000; int i_loop2 = 0; int i_loop2_max = 32000; int i_loop3 = 0; int i_loop3_max = 10;
The core is this thread function:
void *t_calculations(void *param)
{
// current date/time based on current system
time_t now = time(0);
int i_counter = 0;
int i_counter_char = 0;
// convert now to string form
char* dt_now = ctime(&now);
printf("Starting thread ");
cout << dt_now << "\n";
for (i_loop1 = 0; i_loop1<i_loop_max; i_loop1++)
{
for (i_loop2 = 0; i_loop2<i_loop2_max; i_loop2++)
{
for (i_loop3 = 0; i_loop3<i_loop3_max; i_loop3++) {
// Increment test
i_counter++;
// If test and assignement
if (i_counter > 32000) {
i_counter = 0;
}
// Char test
s_tmp_copy[0] = s_cmips[i_counter_char];
i_counter_char++;
if (i_counter_char > 49) {
i_counter_char = 0;
}
}
}
}
time_t now_end = time(0);
// convert now to string form
char* dt_now_end = ctime(&now_end);
printf("End thread at ");
cout << dt_now_end << "\n";
i_finished_threads++;
return NULL;
}
The timestamps is calculated:
static timestamp_t get_timestamp ()
{
struct timeval now;
gettimeofday (&now, NULL);
return now.tv_usec + (timestamp_t)now.tv_sec * 1000000;
}
After all the threads finish main calculates:
// Process
timestamp_t t1 = get_timestamp();
double secs = (t1 - t0) / 1000000.0L;
int cmips = (1 / secs) * 1000000;