It was supposed not to happen. I believed that Amazon had very good, redundant, systems.
I understood when an hurricane hit them in 2012 and I had some Servers in the US down, and had to check for data integrity (that time I had no noticeable losses), but this time it happens to be in Europe, concretely in Ireland zone, without any heavy climate issue, and they totally lost my instance disk, and I got no reasonable explanation, neither a line or reason that could give me some peace of mind and make me thing that this will not never ever happen again and that I can trust the platform.
I just received this email. They sent me without any action by my part. At the beginning I thought it was an Scam. I just could not believe that an email so cold, lacking humanity, letting me down without giving me any alternative, no compensation, without an email address to reply, phone to call for an explanation, no one signing it… was sent by Amazon. Improper of them.
When I log in in the panel I saw it. The volume shows “error”.
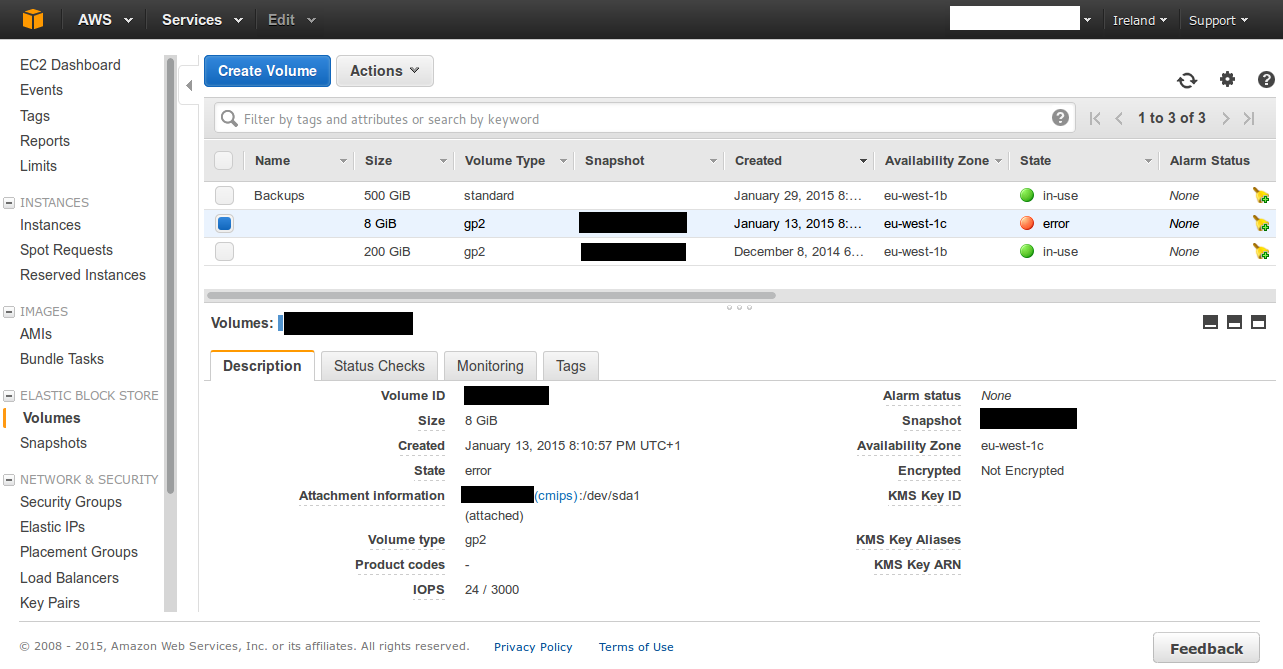
Sadly is not possible to create an snapshot…
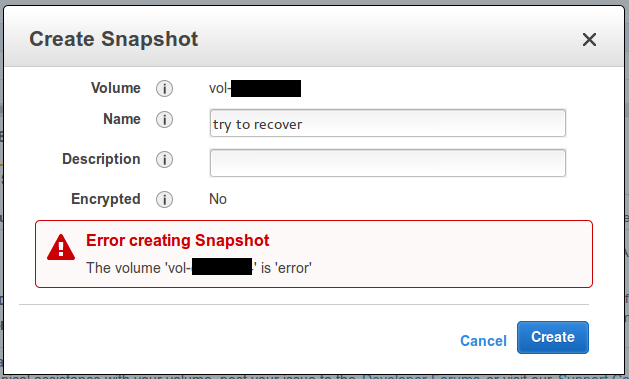
The volume was created on the 13th January 2015, and was the disk of the best instance available, the new c4.8xlarge so what is the point in Amazon email talking about durability?. What about the SLA?.
I really like the Amazon Engineering Teams, but as company this time they really screwed it up.
I wrote to one of my friends, manager in Amazon, that I met when I was finalist in a process there, to just share this, as what happen and the automatic email is just unacceptable. I know they are concerned by quality and good service to clients.
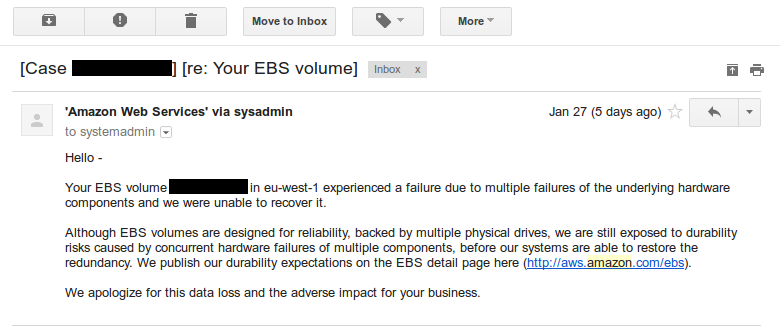
Here is the automatic email they sent me in text, just edited the ids with word number:
[Case number] [re: Your EBS volume]
X-Original-From: Amazon Web Services <[email protected]> Reply-To: Amazon Web Services <[email protected]> Hello - Your EBS volume vol-number in eu-west-1 experienced a failure due to multiple failures of the underlying hardware components and we were unable to recover it. Although EBS volumes are designed for reliability, backed by multiple physical drives, we are still exposed to durability risks caused by concurrent hardware failures of multiple components, before our systems are able to restore the redundancy. We publish our durability expectations on the EBS detail page here (http://aws.amazon.com/ebs). We apologize for this data loss and the adverse impact for your business.
Imagine my face, as CTO, that decided in favor of Amazon, having vouchers of 65,000 USD from Microsoft Azure, and 10,000 USD from Google Cloud, having to explain to the CEO and to the investors that the Cloud provider I choose, and we are paying for -One c4.8xlarge costs ~ 1,000 USD/month- killed irreversibly one of our servers.
I keep my backups in the Cloud as snapshots for speed and autoscaling, for the obvious advantages, but I always keep everything backuped also outside, as well, in house and in several geographic locations, just to prevent “impossible”/unbelievable things like that.
But in normal situations and for 99,99% of companies is impossible not to loss data if your Cloud provider just wipes your disk. And the worst thing is a matter of losing trust.
Amazon makes their durability guarantees for EBS pretty clear IMO; it’s your fault, not theirs, for making unwarranted assumptions about durability. EBS was never designed for S3-like durability and AWS has never claimed otherwise. See http://aws.amazon.com/ebs/details/#availabilityanddurability
Hi Tobin,
I understand that you appreciate Amazon and want to defend them for obvious reasons, I also appreciate them, but what happened was unacceptable for several reasons:
1) The way the email is expressed is horrible.
You trust a provider that lets you down and you get this horrible email. Honestly I though it was spam until I realized that it was not a joke. Customer deserve something better.
2) You don’t expect your provider to have such problems. You trust them and believe they have a lot of redundancy.
You really feel not safe after this message.
3) Amazon page about EBS durability claims other virtues:
“Amazon EBS Availability and Durability
Amazon EBS volumes are designed to be highly available and reliable. At no additional charge to you, Amazon EBS volume data is replicated across multiple servers in an Availability Zone to prevent the loss of data from the failure of any single component. For more details, see the Amazon EC2 and EBS Service Level Agreement.
Amazon EBS volumes are designed for an annual failure rate (AFR) of between 0.1% – 0.2%, where failure refers to a complete or partial loss of the volume, depending on the size and performance of the volume. This makes EBS volumes 20 times more reliable than typical commodity disk drives, which fail with an AFR of around 4%. EBS also supports a snapshot feature, which is a good way to take point-in-time backups of your data. ”
4) EBS durability has nothing to do with this.
You create a fresh new VM, and it can die because the disks assigned to you are old or damaged.
Your VM is new, the hardware assigned is old.
As customer you have no control over this and this can random happen to any one.
5) My VM was stopped for weeks
This VM was not used for some weeks, as it was a devel/test machine, and so it was stopped.
Any mechanism to replicate data have had to happen months ago.
The website says “Amazon EBS volume data is replicated across multiple servers in an Availability Zone to prevent the loss of data from the failure of any single component”.
If you can explain it to me. If my volume was replicated across multiple servers how is possible that (an stopped volume) was lost?.
May I assume that they are lying and that the redundancy mechanism are raid 5 at best in one single NAS?, or that I had very bad luck and all the servers that contained the replicas of my volume died?. If many Amazon servers died at the same time resulting in my data lost, should I or other customers feel confident?.
The fact that my VM was lost, specially being stopped, kills my confidence in a hard way.
6) After reporting this to a friend in the Company I got a call from two PM. They were nice, and they told me that they will improve the message to customers and that what happened with my volume was extremely rare.
They could not provide technical info on the underlying hardware components, so I don’t feel much safe.
7) I think Amazon make great efforts to bring very good service to Customers (in all their areas, not just AWS).
But I think this time they failed and they have to improve.
Best,
Carles
Hi! Searching google i’ve found you post, unfortunately i hadn’t such luck, and my main production environment is lost… The same error, and believe me, the same email message… I still can’t believe…
I thought that snapshot feature was just for scaling and new instances, not for backup, i believed in the main EBS page text: “Each Amazon EBS volume is automatically replicated within its Availability Zone to protect you from component failure, offering high availability and durability.”. Maybe my understanding of replication is wrong…
My confidence in the service has broken in million pieces, and one week earlier i just renewed my reserved instance… 🙁
I know how you feel.
It is very sad. And I’m sorry that you experienced such bad situation of your Production Server being wiped by an internal error from Amazon. Is very frustrating.
The quality of service of Amazon is being very disappointing.
Thanks for sharing your experience and specially the fact that they have not changed the email sent.
I expected that after I spoke with the two PMs of Amazon, at least they would had changed that horrible message to a more human. It is sad to see that apparently they improved nothing. 🙁